 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnd2End Multi-View Feature Matching using Differentiable Pose Optimization
Paper and Code
May 03, 2022


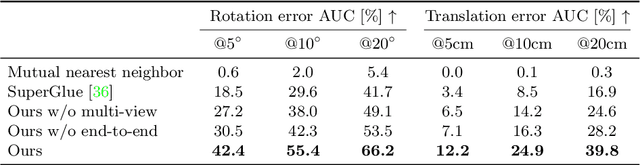
Learning-based approaches have become indispensable for camera pose estimation. However, feature detection, description, matching, and pose optimization are often approached in an isolated fashion. In particular, erroneous feature matches have severe impact on subsequent camera pose estimation and often require additional measures such as outlier rejection. Our method tackles this challenge by addressing feature matching and pose optimization jointly: first, we integrate information from multiple views into the matching by spanning a graph attention network across multiple frames to predict their matches all at once. Second, the resulting matches along with their predicted confidences are used for robust pose optimization with a differentiable Gauss-Newton solver. End-to-end training combined with multi-view feature matching boosts the pose estimation metrics compared to SuperGlue by 8.9% on ScanNet and 10.7% on MegaDepth on average. Our approach improves both pose estimation and matching accuracy over state-of-the-art matching networks. Training feature matching across multiple views with gradients from pose optimization naturally learns to disregard outliers, thereby rendering additional outlier handling unnecessary, which is highly desirable for pose estimation systems.