 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnd-to-end Speech Recognition with Adaptive Computation Steps
Paper and Code
Sep 26, 2018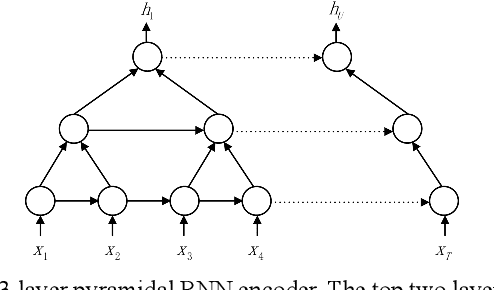

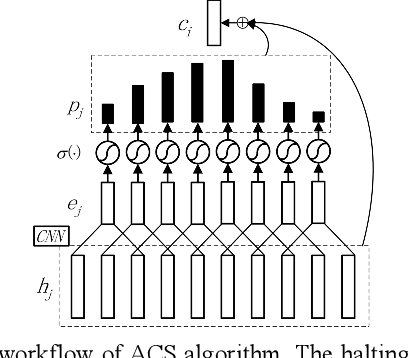
In this paper, we present Adaptive Computation Steps (ACS) algo-rithm, which enables end-to-end speech recognition models to dy-namically decide how many frames should be processed to predict a linguistic output. The model that applies ACS algorithm follows the encoder-decoder framework, while unlike the attention-based mod-els, it produces alignments independently at the encoder side using the correlation between adjacent frames. Thus, predictions can be made as soon as sufficient acoustic information is received, which makes the model applicable in online cases. Besides, a small change is made to the decoding stage of the encoder-decoder framework, which allows the prediction to exploit bidirectional contexts. We verify the ACS algorithm on a Mandarin speech corpus AIShell-1, and it achieves a 31.2% CER in the online occasion, compared to the 32.4% CER of the attention-based model. To fully demonstrate the advantage of ACS algorithm, offline experiments are conducted, in which our ACS model achieves an 18.7% CER, outperforming the attention-based counterpart with the CER of 22.0%.