 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnd-to-end Learning of Deterministic Decision Trees
Paper and Code
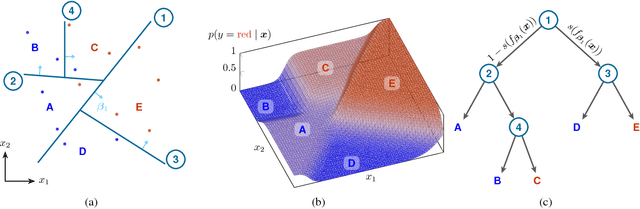
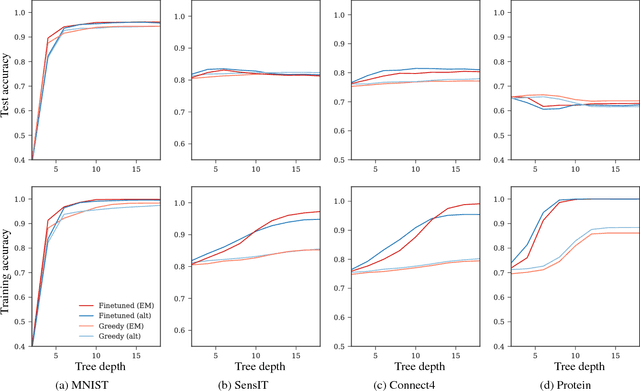
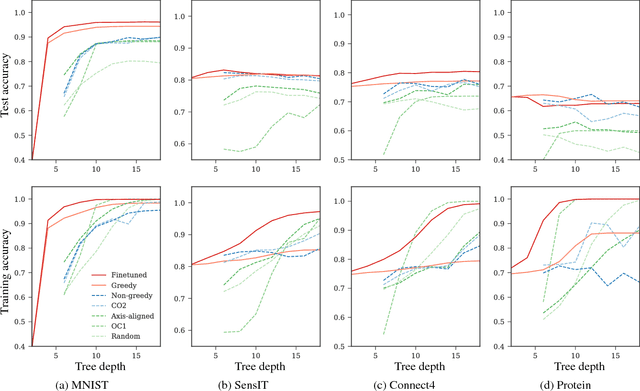

Conventional decision trees have a number of favorable properties, including interpretability, a small computational footprint and the ability to learn from little training data. However, they lack a key quality that has helped fuel the deep learning revolution: that of being end-to-end trainable, and to learn from scratch those features that best allow to solve a given supervised learning problem. Recent work (Kontschieder 2015) has addressed this deficit, but at the cost of losing a main attractive trait of decision trees: the fact that each sample is routed along a small subset of tree nodes only. We here propose a model and Expectation-Maximization training scheme for decision trees that are fully probabilistic at train time, but after a deterministic annealing process become deterministic at test time. We also analyze the learned oblique split parameters on image datasets and show that Neural Networks can be trained at each split node. In summary, we present the first end-to-end learning scheme for deterministic decision trees and present results on par with or superior to published standard oblique decision tree algorithms.