 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnd-to-end Learning of Cost-Volume Aggregation for Real-time Dense Stereo
Paper and Code
Nov 17, 2016

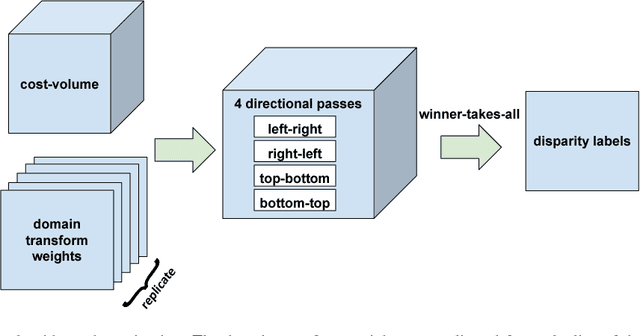

We present a new deep learning-based approach for dense stereo matching. Compared to previous works, our approach does not use deep learning of pixel appearance descriptors, employing very fast classical matching scores instead. At the same time, our approach uses a deep convolutional network to predict the local parameters of cost volume aggregation process, which in this paper we implement using differentiable domain transform. By treating such transform as a recurrent neural network, we are able to train our whole system that includes cost volume computation, cost-volume aggregation (smoothing), and winner-takes-all disparity selection end-to-end. The resulting method is highly efficient at test time, while achieving good matching accuracy. On the KITTI 2015 benchmark, it achieves a result of 6.34\% error rate while running at 29 frames per second rate on a modern GPU.