 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnd-to-end 3D shape inverse rendering of different classes of objects from a single input image
Paper and Code
Nov 11, 2017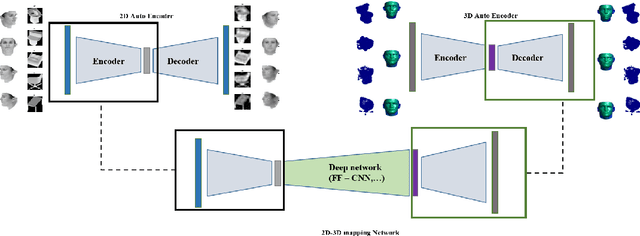
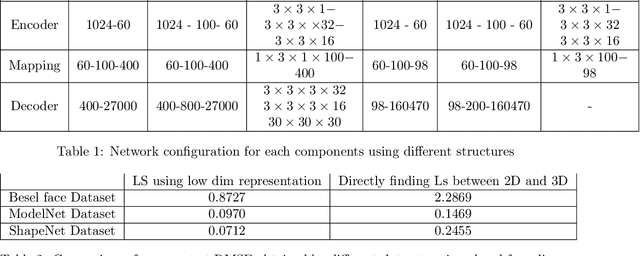


In this paper a semi-supervised deep framework is proposed for the problem of 3D shape inverse rendering from a single 2D input image. The main structure of proposed framework consists of unsupervised pre-trained components which significantly reduce the need to labeled data for training the whole framework. using labeled data has the advantage of achieving to accurate results without the need to predefined assumptions about image formation process. Three main components are used in the proposed network: an encoder which maps 2D input image to a representation space, a 3D decoder which decodes a representation to a 3D structure and a mapping component in order to map 2D to 3D representation. The only part that needs label for training is the mapping part with not too many parameters. The other components in the network can be pre-trained unsupervised using only 2D images or 3D data in each case. The way of reconstructing 3D shapes in the decoder component, inspired by the model based methods for 3D reconstruction, maps a low dimensional representation to 3D shape space with the advantage of extracting the basis vectors of shape space from training data itself and is not restricted to a small set of examples as used in predefined models. Therefore, the proposed framework deals directly with coordinate values of the point cloud representation which leads to achieve dense 3D shapes in the output. The experimental results on several benchmark datasets of objects and human faces and comparing with recent similar methods shows the power of proposed network in recovering more details from single 2D images.