 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEmpirical entropy, minimax regret and minimax risk
Paper and Code
Jul 03, 2017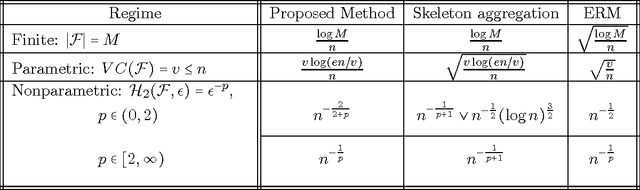
We consider the random design regression model with square loss. We propose a method that aggregates empirical minimizers (ERM) over appropriately chosen random subsets and reduces to ERM in the extreme case, and we establish sharp oracle inequalities for its risk. We show that, under the $\varepsilon^{-p}$ growth of the empirical $\varepsilon$-entropy, the excess risk of the proposed method attains the rate $n^{-2/(2+p)}$ for $p\in(0,2)$ and $n^{-1/p}$ for $p>2$ where $n$ is the sample size. Furthermore, for $p\in(0,2)$, the excess risk rate matches the behavior of the minimax risk of function estimation in regression problems under the well-specified model. This yields a conclusion that the rates of statistical estimation in well-specified models (minimax risk) and in misspecified models (minimax regret) are equivalent in the regime $p\in(0,2)$. In other words, for $p\in(0,2)$ the problem of statistical learning enjoys the same minimax rate as the problem of statistical estimation. On the contrary, for $p>2$ we show that the rates of the minimax regret are, in general, slower than for the minimax risk. Our oracle inequalities also imply the $v\log(n/v)/n$ rates for Vapnik-Chervonenkis type classes of dimension $v$ without the usual convexity assumption on the class; we show that these rates are optimal. Finally, for a slightly modified method, we derive a bound on the excess risk of $s$-sparse convex aggregation improving that of Lounici [Math. Methods Statist. 16 (2007) 246-259] and providing the optimal rate.