 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEmpirical Analysis of Lifelog Data using Optimal Feature Selection based Unsupervised Logistic Regression (OFS-ULR) Model with Spark Streaming
Paper and Code
Apr 12, 2022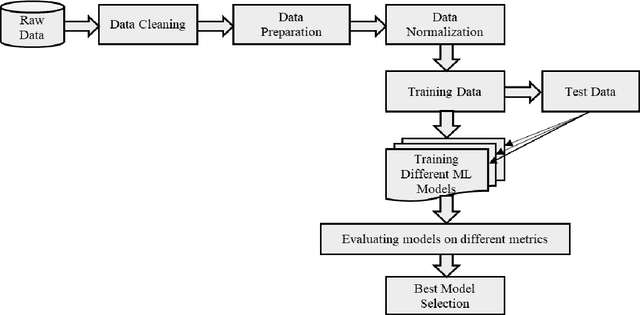


Recent advancement in the field of pervasive healthcare monitoring systems causes the generation of a huge amount of lifelog data in real-time. Chronic diseases are one of the most serious health challenges in developing and developed countries. According to WHO, this accounts for 73% of all deaths and 60% of the global burden of diseases. Chronic disease classification models are now harnessing the potential of lifelog data to explore better healthcare practices. This paper is to construct an optimal feature selection-based unsupervised logistic regression model (OFS-ULR) to classify chronic diseases. Since lifelog data analysis is crucial due to its sensitive nature; thus the conventional classification models show limited performance. Therefore, designing new classifiers for the classification of chronic diseases using lifelog data is the need of the age. The vital part of building a good model depends on pre-processing of the dataset, identifying important features, and then training a learning algorithm with suitable hyper parameters for better performance. The proposed approach improves the performance of existing methods using a series of steps such as (i) removing redundant or invalid instances, (ii) making the data labelled using clustering and partitioning the data into classes, (iii) identifying the suitable subset of features by applying either some domain knowledge or selection algorithm, (iv) hyper parameter tuning for models to get best results, and (v) performance evaluation using Spark streaming environment. For this purpose, two-time series datasets are used in the experiment to compute the accuracy, recall, precision, and f1-score. The experimental analysis proves the suitability of the proposed approach as compared to the conventional classifiers and our newly constructed model achieved highest accuracy and reduced training complexity among all among all.