 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEmotional Speech Recognition with Pre-trained Deep Visual Models
Paper and Code
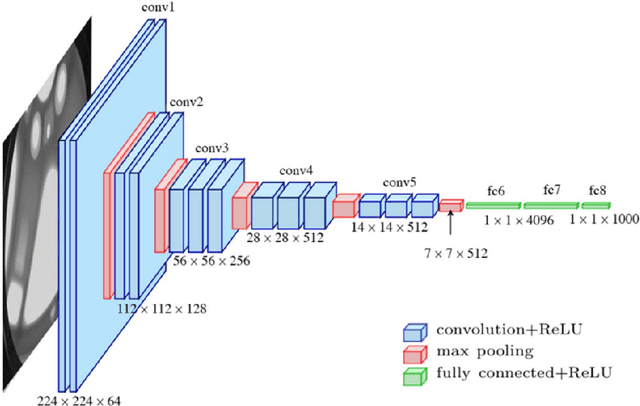
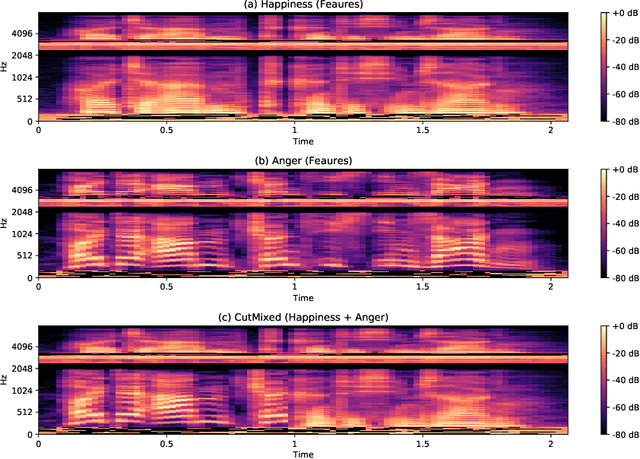
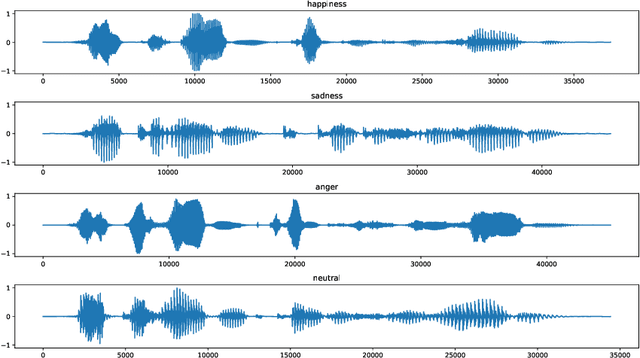

In this paper, we propose a new methodology for emotional speech recognition using visual deep neural network models. We employ the transfer learning capabilities of the pre-trained computer vision deep models to have a mandate for the emotion recognition in speech task. In order to achieve that, we propose to use a composite set of acoustic features and a procedure to convert them into images. Besides, we present a training paradigm for these models taking into consideration the different characteristics between acoustic-based images and regular ones. In our experiments, we use the pre-trained VGG-16 model and test the overall methodology on the Berlin EMO-DB dataset for speaker-independent emotion recognition. We evaluate the proposed model on the full list of the seven emotions and the results set a new state-of-the-art.