 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEmbedding Power Flow into Machine Learning for Parameter and State Estimation
Paper and Code
Mar 26, 2021
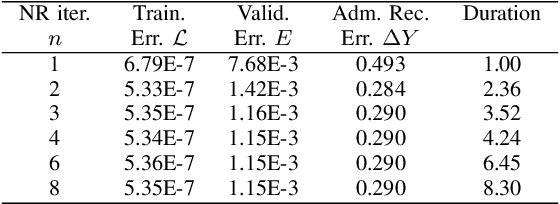


Modern state and parameter estimations in power systems consist of two stages: the outer problem of minimizing the mismatch between network observation and prediction over the network parameters, and the inner problem of predicting the system state for given values of the parameters. The standard solution of the combined problem is iterative: (a) set the parameters, e.g. to priors on the power line characteristics, (b) map input observation to prediction of the output, (c) compute the mismatch between predicted and observed output, (d) make a gradient descent step in the space of parameters to minimize the mismatch, and loop back to (a). We show how modern Machine Learning (ML), and specifically training guided by automatic differentiation, allows to resolve the iterative loop more efficiently. Moreover, we extend the scheme to the case of incomplete observations, where Phasor Measurement Units (reporting real and reactive powers, voltage and phase) are available only at the generators (PV buses), while loads (PQ buses) report (via SCADA controls) only active and reactive powers. Considering it from the implementation perspective, our methodology of resolving the parameter and state estimation problem can be viewed as embedding of the Power Flow (PF) solver into the training loop of the Machine Learning framework (PyTorch, in this study). We argue that this embedding can help to resolve high-level optimization problems in power system operations and planning.