 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEmbedding Comparator: Visualizing Differences in Global Structure and Local Neighborhoods via Small Multiples
Paper and Code
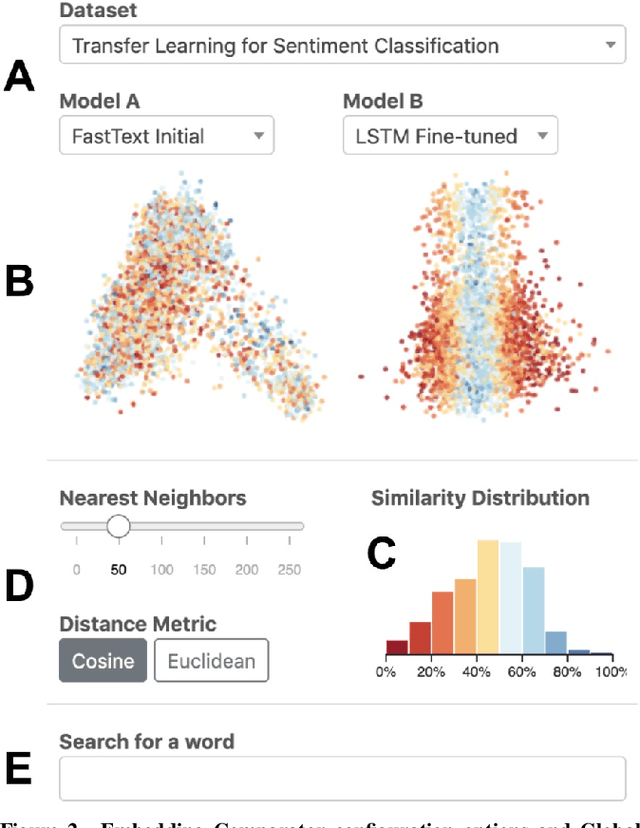
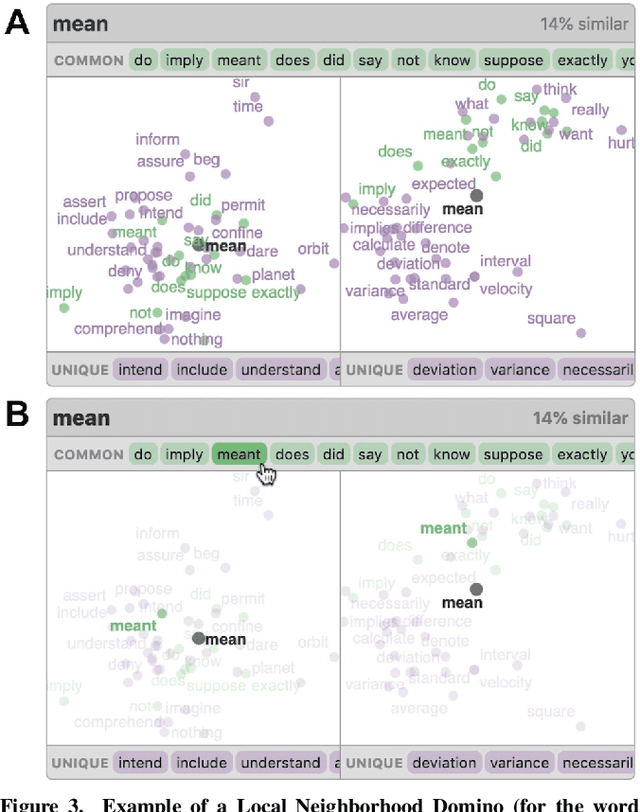
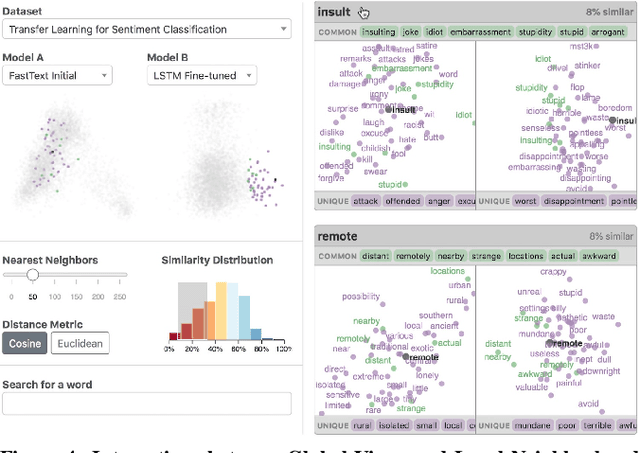
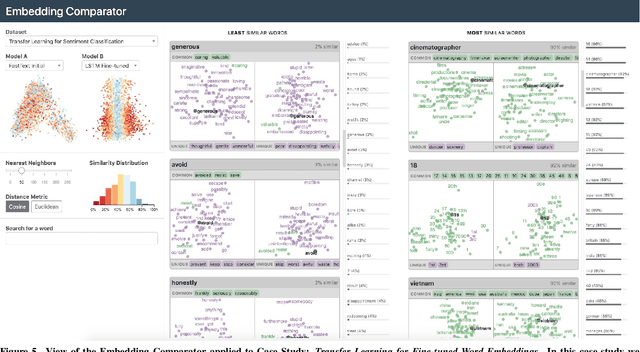
Embeddings -- mappings from high-dimensional discrete input to lower-dimensional continuous vector spaces -- have been widely adopted in machine learning, linguistics, and computational biology as they often surface interesting and unexpected domain semantics. Through semi-structured interviews with embedding model researchers and practitioners, we find that current tools poorly support a central concern: comparing different embeddings when developing fairer, more robust models. In response, we present the Embedding Comparator, an interactive system that balances gaining an overview of the embedding spaces with making fine-grained comparisons of local neighborhoods. For a pair of models, we compute the similarity of the k-nearest neighbors of every embedded object, and visualize the results as Local Neighborhood Dominoes: small multiples that facilitate rapid comparisons. Using case studies, we illustrate the types of insights the Embedding Comparator reveals including how fine-tuning embeddings changes semantics, how language changes over time, and how training data differences affect two seemingly similar models.