 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEmbedded Deployment of Semantic Segmentation in Medicine through Low-Resolution Inputs
Paper and Code
Mar 08, 2024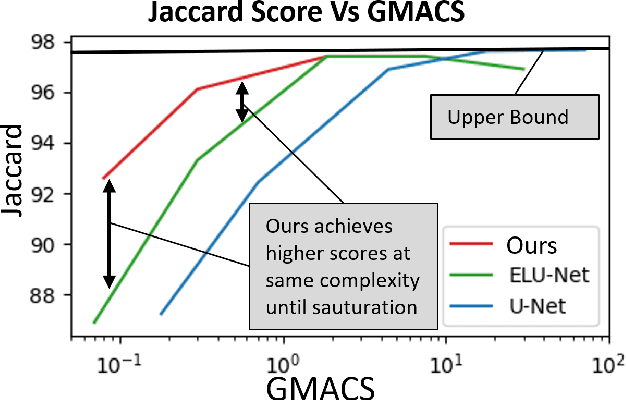
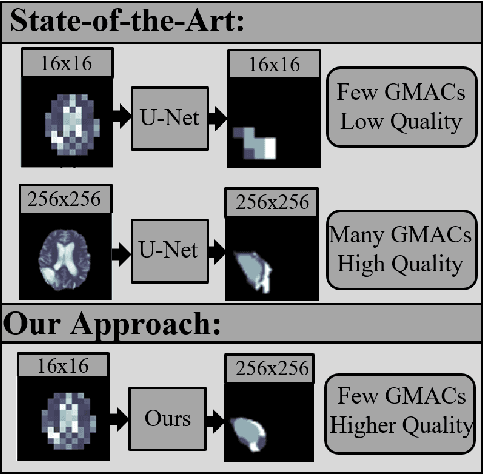


When deploying neural networks in real-life situations, the size and computational effort are often the limiting factors. This is especially true in environments where big, expensive hardware is not affordable, like in embedded medical devices, where budgets are often tight. State-of-the-art proposed multiple different lightweight solutions for such use cases, mostly by changing the base model architecture, not taking the input and output resolution into consideration. In this paper, we propose our architecture that takes advantage of the fact that in hardware-limited environments, we often refrain from using the highest available input resolutions to guarantee a higher throughput. Although using lower-resolution input leads to a significant reduction in computing and memory requirements, it may also incur reduced prediction quality. Our architecture addresses this problem by exploiting the fact that we can still utilize high-resolution ground-truths in training. The proposed model inputs lower-resolution images and high-resolution ground truths, which can improve the prediction quality by 5.5% while adding less than 200 parameters to the model. %reducing the frames per second only from 25 to 20. We conduct an extensive analysis to illustrate that our architecture enhances existing state-of-the-art frameworks for lightweight semantic segmentation of cancer in MRI images. We also tested the deployment speed of state-of-the-art lightweight networks and our architecture on Nvidia's Jetson Nano to emulate deployment in resource-constrained embedded scenarios.