 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEMaQ: Expected-Max Q-Learning Operator for Simple Yet Effective Offline and Online RL
Paper and Code

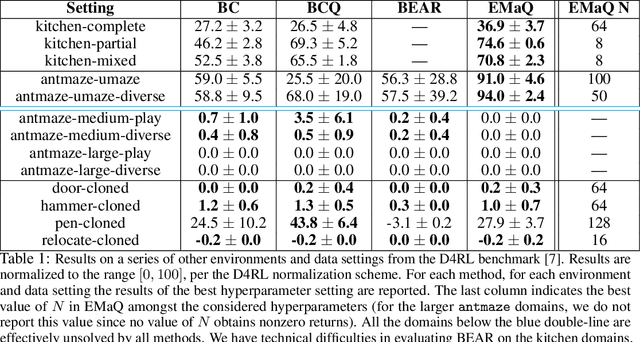


Off-policy reinforcement learning (RL) holds the promise of sample-efficient learning of decision-making policies by leveraging past experience. However, in the offline RL setting -- where a fixed collection of interactions are provided and no further interactions are allowed -- it has been shown that standard off-policy RL methods can significantly underperform. Recently proposed methods aim to address this shortcoming by regularizing learned policies to remain close to the given dataset of interactions. However, these methods involve several configurable components such as learning a separate policy network on top of a behavior cloning actor, and explicitly constraining action spaces through clipping or reward penalties. Striving for simultaneous simplicity and performance, in this work we present a novel backup operator, Expected-Max Q-Learning (EMaQ), which naturally restricts learned policies to remain within the support of the offline dataset \emph{without any explicit regularization}, while retaining desirable theoretical properties such as contraction. We demonstrate that EMaQ is competitive with Soft Actor Critic (SAC) in online RL, and surpasses SAC in the deployment-efficient setting. In the offline RL setting -- the main focus of this work -- through EMaQ we are able to make important observations regarding key components of offline RL, and the nature of standard benchmark tasks. Lastly but importantly, we observe that EMaQ achieves state-of-the-art performance with fewer moving parts such as one less function approximation, making it a strong, yet easy to implement baseline for future work.