 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Video to Audio Mapper with Visual Scene Detection
Paper and Code
Sep 15, 2024

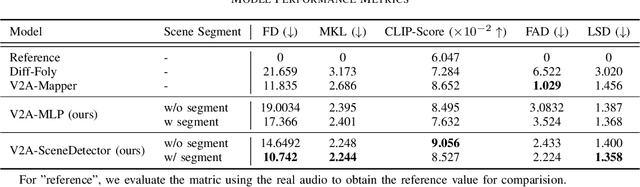
Video-to-audio (V2A) generation aims to produce corresponding audio given silent video inputs. This task is particularly challenging due to the cross-modality and sequential nature of the audio-visual features involved. Recent works have made significant progress in bridging the domain gap between video and audio, generating audio that is semantically aligned with the video content. However, a critical limitation of these approaches is their inability to effectively recognize and handle multiple scenes within a video, often leading to suboptimal audio generation in such cases. In this paper, we first reimplement a state-of-the-art V2A model with a slightly modified light-weight architecture, achieving results that outperform the baseline. We then propose an improved V2A model that incorporates a scene detector to address the challenge of switching between multiple visual scenes. Results on VGGSound show that our model can recognize and handle multiple scenes within a video and achieve superior performance against the baseline for both fidelity and relevance.