 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient, Uncertainty-based Moderation of Neural Networks Text Classifiers
Paper and Code

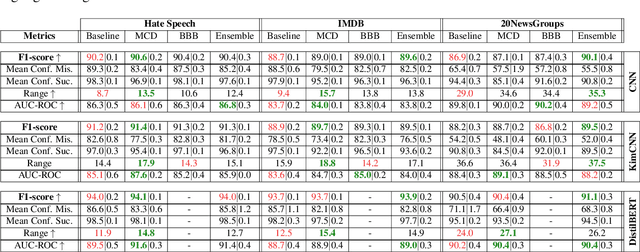

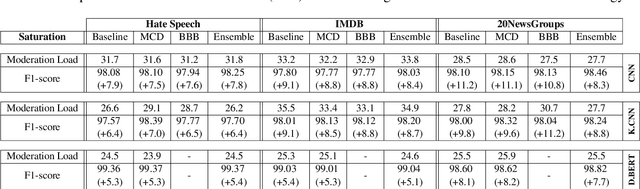
To maximize the accuracy and increase the overall acceptance of text classifiers, we propose a framework for the efficient, in-operation moderation of classifiers' output. Our framework focuses on use cases in which F1-scores of modern Neural Networks classifiers (ca.~90%) are still inapplicable in practice. We suggest a semi-automated approach that uses prediction uncertainties to pass unconfident, probably incorrect classifications to human moderators. To minimize the workload, we limit the human moderated data to the point where the accuracy gains saturate and further human effort does not lead to substantial improvements. A series of benchmarking experiments based on three different datasets and three state-of-the-art classifiers show that our framework can improve the classification F1-scores by 5.1 to 11.2% (up to approx.~98 to 99%), while reducing the moderation load up to 73.3% compared to a random moderation.