Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Training Convolutional Neural Networks on Edge Devices with Gradient-pruned Sign-symmetric Feedback Alignment
Paper and Code
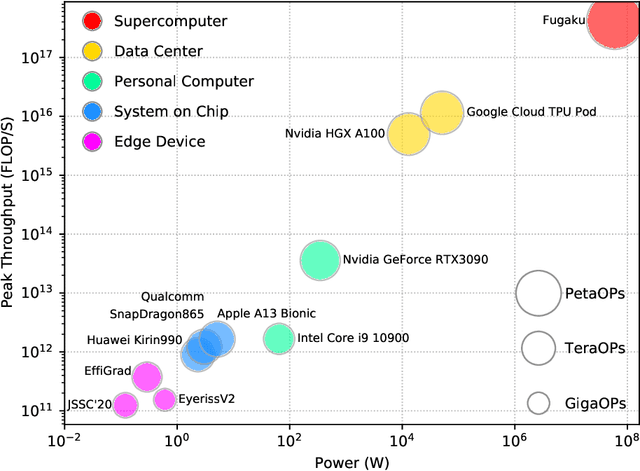
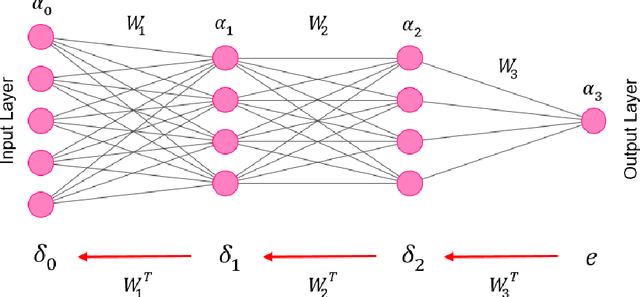
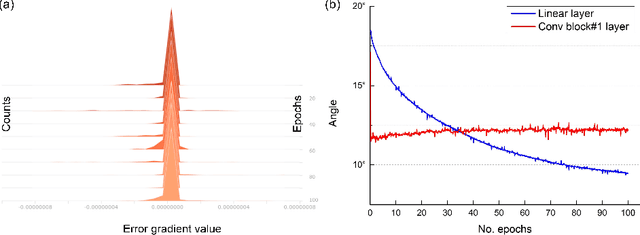
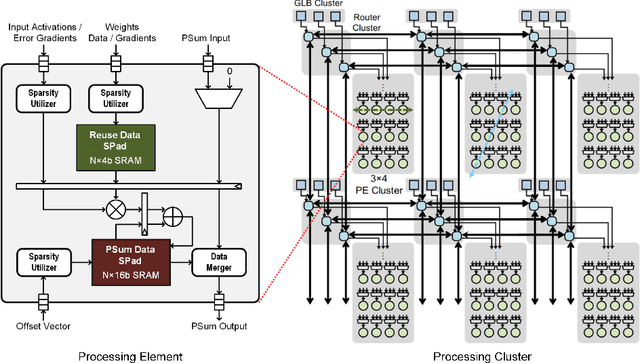
With the prosperity of mobile devices, the distributed learning approach enabling model training with decentralized data has attracted wide research. However, the lack of training capability for edge devices significantly limits the energy efficiency of distributed learning in real life. This paper describes a novel approach of training DNNs exploiting the redundancy and the weight asymmetry potential of conventional backpropagation. We demonstrate that with negligible classification accuracy loss, the proposed approach outperforms the prior arts by 5x in terms of energy efficiency.
View paper on