 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Sparse Spherical k-Means for Document Clustering
Paper and Code
Jul 30, 2021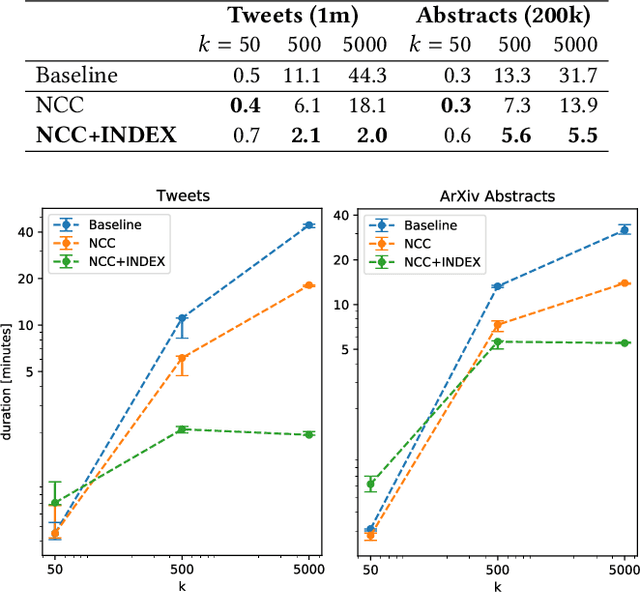
Spherical k-Means is frequently used to cluster document collections because it performs reasonably well in many settings and is computationally efficient. However, the time complexity increases linearly with the number of clusters k, which limits the suitability of the algorithm for larger values of k depending on the size of the collection. Optimizations targeted at the Euclidean k-Means algorithm largely do not apply because the cosine distance is not a metric. We therefore propose an efficient indexing structure to improve the scalability of Spherical k-Means with respect to k. Our approach exploits the sparsity of the input vectors and the convergence behavior of k-Means to reduce the number of comparisons on each iteration significantly.