 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Sketching Algorithm for Sparse Binary Data
Paper and Code
Oct 10, 2019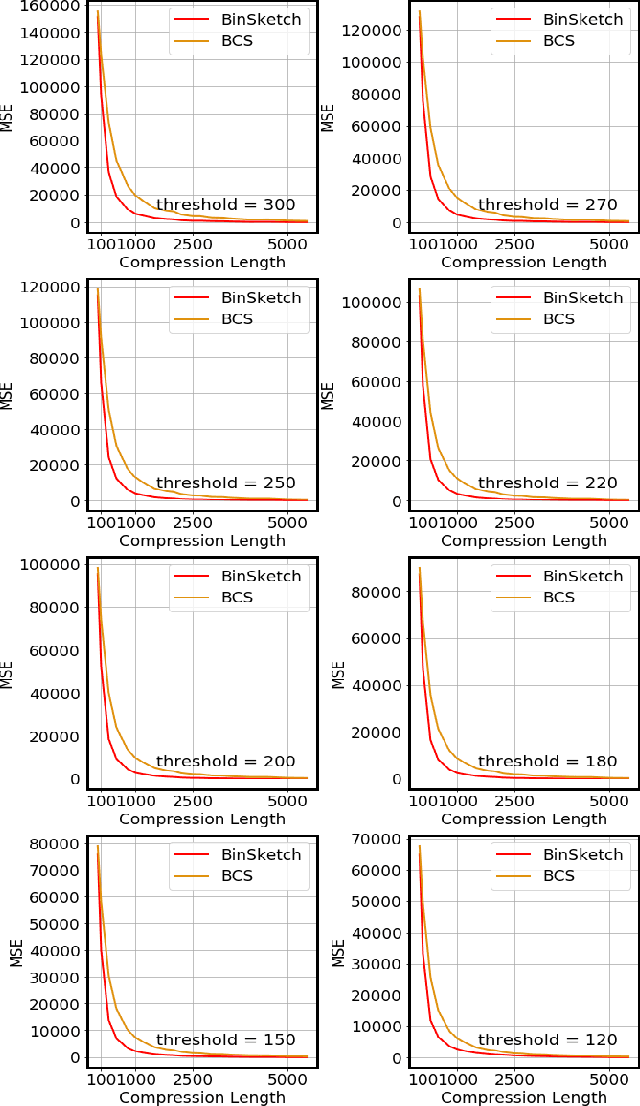
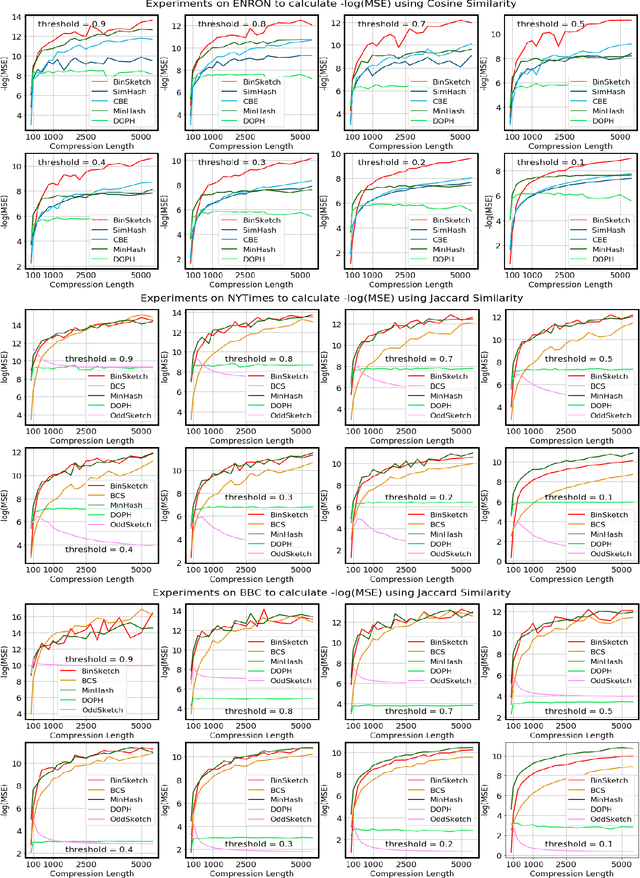
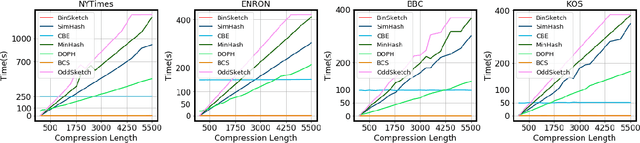
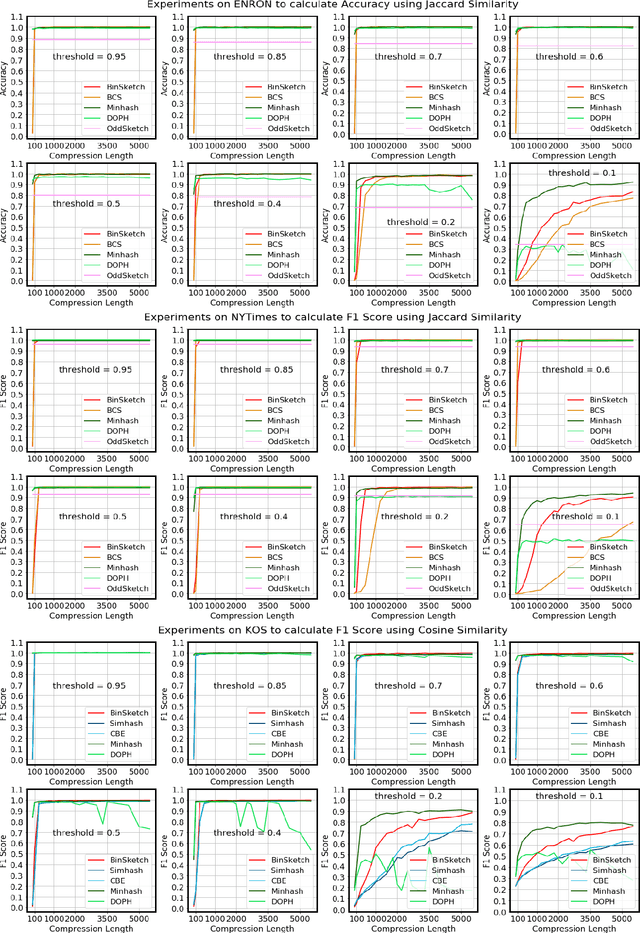
Recent advancement of the WWW, IOT, social network, e-commerce, etc. have generated a large volume of data. These datasets are mostly represented by high dimensional and sparse datasets. Many fundamental subroutines of common data analytic tasks such as clustering, classification, ranking, nearest neighbour search, etc. scale poorly with the dimension of the dataset. In this work, we address this problem and propose a sketching (alternatively, dimensionality reduction) algorithm -- $\binsketch$ (Binary Data Sketch) -- for sparse binary datasets. $\binsketch$ preserves the binary version of the dataset after sketching and maintains estimates for multiple similarity measures such as Jaccard, Cosine, Inner-Product similarities, and Hamming distance, on the same sketch. We present a theoretical analysis of our algorithm and complement it with extensive experimentation on several real-world datasets. We compare the performance of our algorithm with the state-of-the-art algorithms on the task of mean-square-error and ranking. Our proposed algorithm offers a comparable accuracy while suggesting a significant speedup in the dimensionality reduction time, with respect to the other candidate algorithms. Our proposal is simple, easy to implement, and therefore can be adopted in practice.