Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Parallel Learning of Word2Vec
Paper and Code
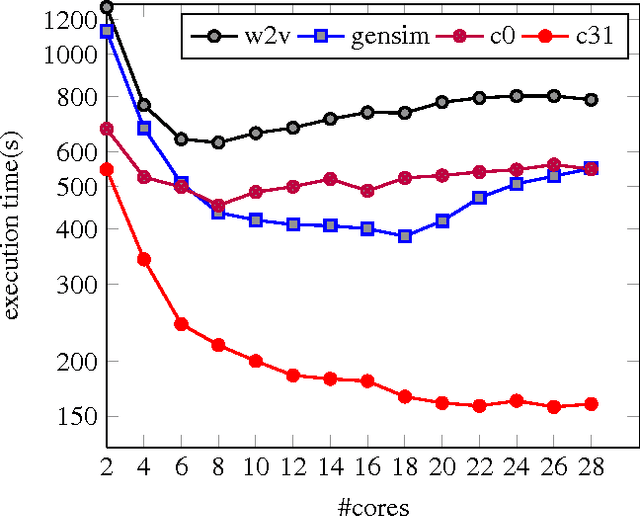


Since its introduction, Word2Vec and its variants are widely used to learn semantics-preserving representations of words or entities in an embedding space, which can be used to produce state-of-art results for various Natural Language Processing tasks. Existing implementations aim to learn efficiently by running multiple threads in parallel while operating on a single model in shared memory, ignoring incidental memory update collisions. We show that these collisions can degrade the efficiency of parallel learning, and propose a straightforward caching strategy that improves the efficiency by a factor of 4.
* ICML 2016 Machine Learning workshop
View paper on