 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient L1-Norm Principal-Component Analysis via Bit Flipping
Paper and Code
Oct 06, 2016
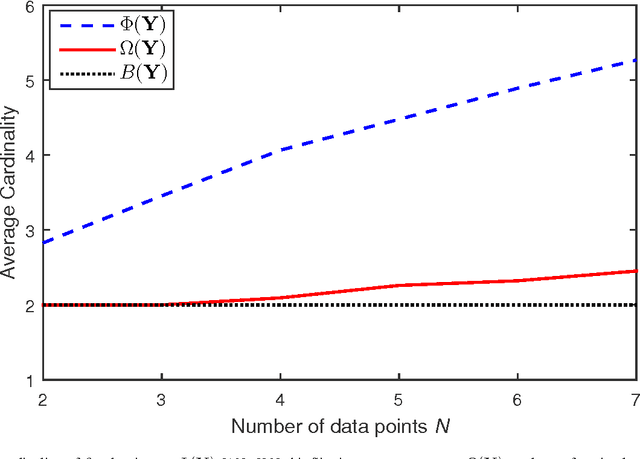
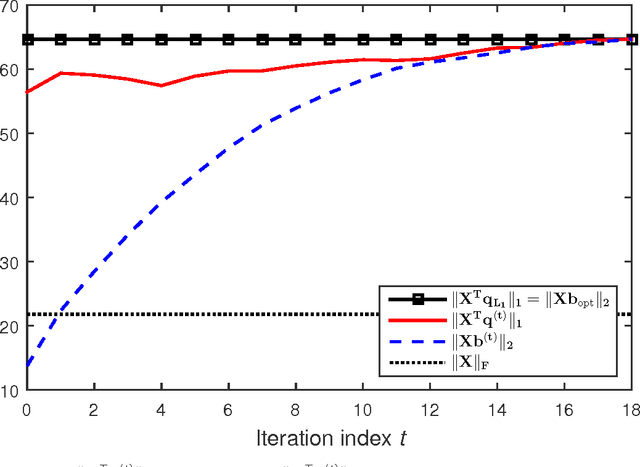
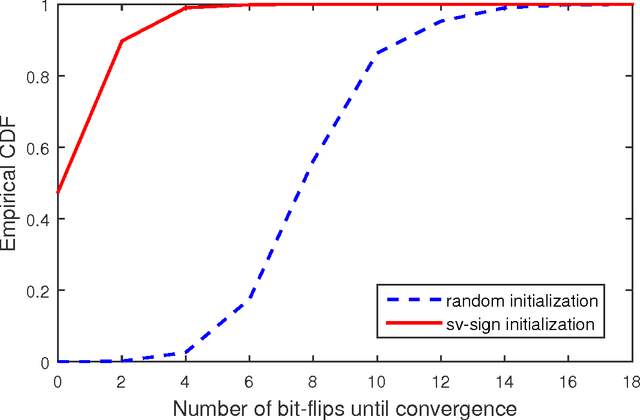
It was shown recently that the $K$ L1-norm principal components (L1-PCs) of a real-valued data matrix $\mathbf X \in \mathbb R^{D \times N}$ ($N$ data samples of $D$ dimensions) can be exactly calculated with cost $\mathcal{O}(2^{NK})$ or, when advantageous, $\mathcal{O}(N^{dK - K + 1})$ where $d=\mathrm{rank}(\mathbf X)$, $K<d$ [1],[2]. In applications where $\mathbf X$ is large (e.g., "big" data of large $N$ and/or "heavy" data of large $d$), these costs are prohibitive. In this work, we present a novel suboptimal algorithm for the calculation of the $K < d$ L1-PCs of $\mathbf X$ of cost $\mathcal O(ND \mathrm{min} \{ N,D\} + N^2(K^4 + dK^2) + dNK^3)$, which is comparable to that of standard (L2-norm) PC analysis. Our theoretical and experimental studies show that the proposed algorithm calculates the exact optimal L1-PCs with high frequency and achieves higher value in the L1-PC optimization metric than any known alternative algorithm of comparable computational cost. The superiority of the calculated L1-PCs over standard L2-PCs (singular vectors) in characterizing potentially faulty data/measurements is demonstrated with experiments on data dimensionality reduction and disease diagnosis from genomic data.