 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Encoders for Streaming Sequence Tagging
Paper and Code
Jan 23, 2023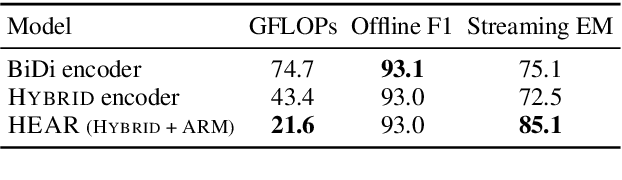
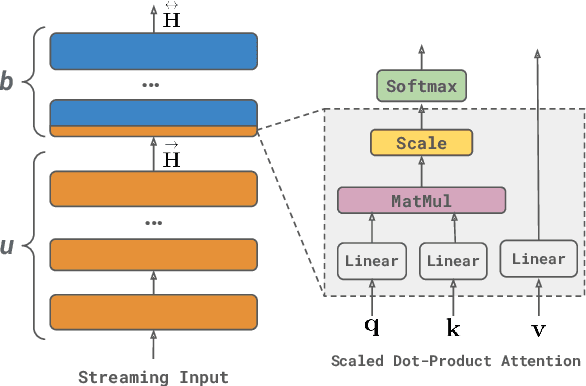

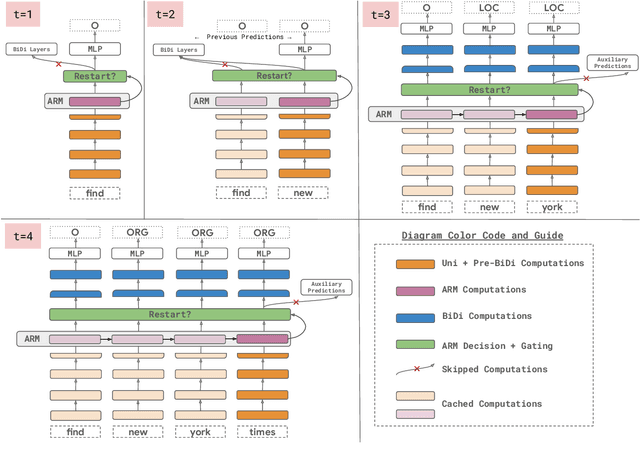
A naive application of state-of-the-art bidirectional encoders for streaming sequence tagging would require encoding each token from scratch for each new token in an incremental streaming input (like transcribed speech). The lack of re-usability of previous computation leads to a higher number of Floating Point Operations (or FLOPs) and higher number of unnecessary label flips. Increased FLOPs consequently lead to higher wall-clock time and increased label flipping leads to poorer streaming performance. In this work, we present a Hybrid Encoder with Adaptive Restart (HEAR) that addresses these issues while maintaining the performance of bidirectional encoders over the offline (or complete) inputs while improving performance on streaming (or incomplete) inputs. HEAR has a Hybrid unidirectional-bidirectional encoder architecture to perform sequence tagging, along with an Adaptive Restart Module (ARM) to selectively guide the restart of bidirectional portion of the encoder. Across four sequence tagging tasks, HEAR offers FLOP savings in streaming settings upto 71.1% and also outperforms bidirectional encoders for streaming predictions by upto +10% streaming exact match.