 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Detection and Filtering Systems for Distributed Training
Paper and Code
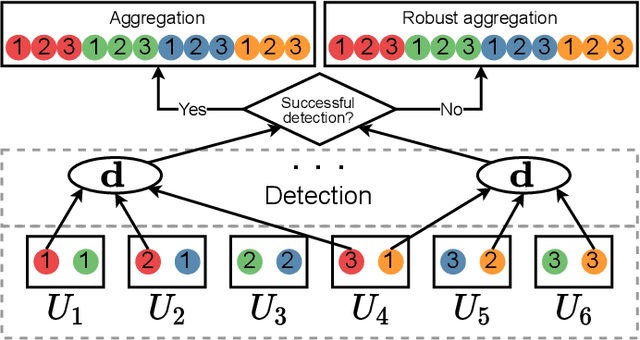
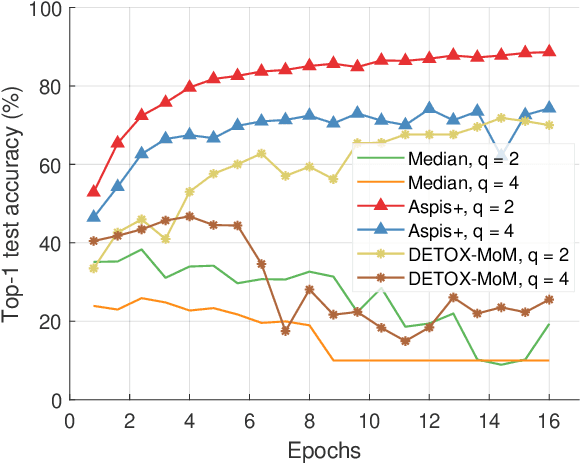
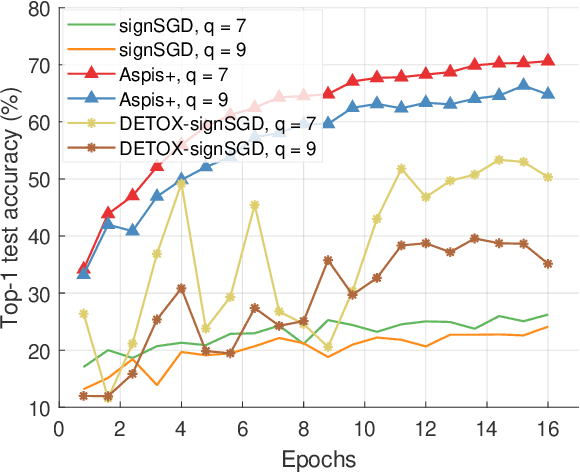

A plethora of modern machine learning tasks requires the utilization of large-scale distributed clusters as a critical component of the training pipeline. However, abnormal Byzantine behavior of the worker nodes can derail the training and compromise the quality of the inference. Such behavior can be attributed to unintentional system malfunctions or orchestrated attacks; as a result, some nodes may return arbitrary results to the parameter server (PS) that coordinates the training. Recent work considers a wide range of attack models and has explored robust aggregation and/or computational redundancy to correct the distorted gradients. In this work, we consider attack models ranging from strong ones: $q$ omniscient adversaries with full knowledge of the defense protocol that can change from iteration to iteration to weak ones: $q$ randomly chosen adversaries with limited collusion abilities that only change every few iterations at a time. Our algorithms rely on redundant task assignments coupled with detection of adversarial behavior. For strong attacks, we demonstrate a reduction in the fraction of distorted gradients ranging from 16%-99% as compared to the prior state-of-the-art. Our top-1 classification accuracy results on the CIFAR-10 data set demonstrate a 25% advantage in accuracy (averaged over strong and weak scenarios) under the most sophisticated attacks compared to state-of-the-art methods.