 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Content-Based Sparse Attention with Routing Transformers
Paper and Code
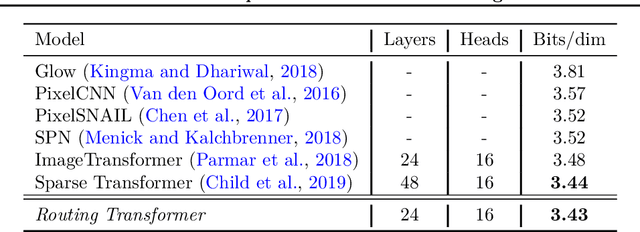
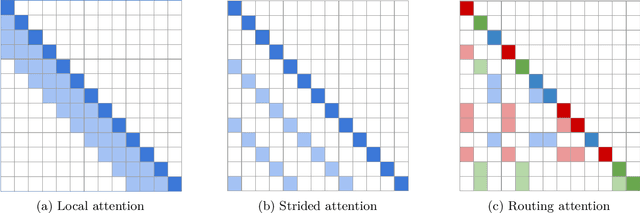
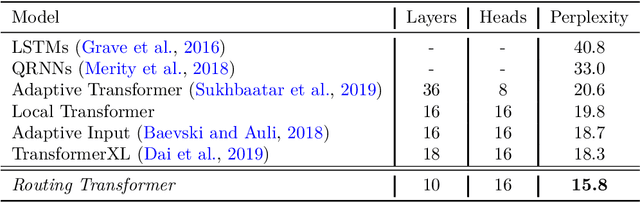

Self-attention has recently been adopted for a wide range of sequence modeling problems. Despite its effectiveness, self-attention suffers from quadratic compute and memory requirements with respect to sequence length. Successful approaches to reduce this complexity focused on attending to local sliding windows or a small set of locations independent of content. Our work proposes to learn dynamic sparse attention patterns that avoid allocating computation and memory to attend to content unrelated to the query of interest. This work builds upon two lines of research: it combines the modeling flexibility of prior work on content-based sparse attention with the efficiency gains from approaches based on local, temporal sparse attention. Our model, the Routing Transformer, endows self-attention with a sparse routing module based on online k-means while reducing the overall complexity of attention to $O\left(n^{1.5}d\right)$ from $O\left(n^2d\right)$ for sequence length $n$ and hidden dimension $d$. We show that our model outperforms comparable sparse attention models on language modeling on Wikitext-103 (15.8 vs 18.3 perplexity) as well as on image generation on ImageNet-64 (3.43 vs 3.44 bits/dim) while using fewer self-attention layers.