 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Approximations of the Fisher Matrix in Neural Networks using Kronecker Product Singular Value Decomposition
Paper and Code
Feb 02, 2022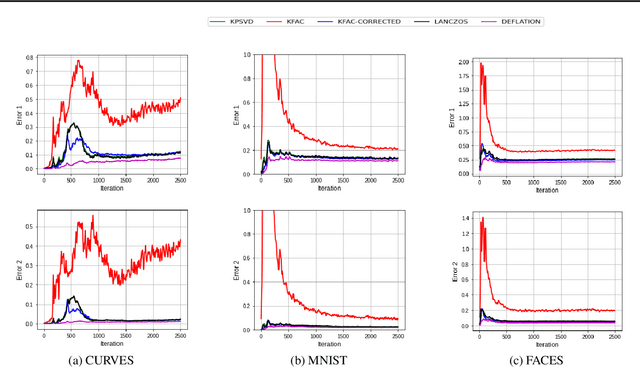
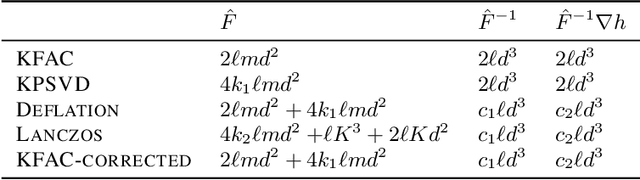
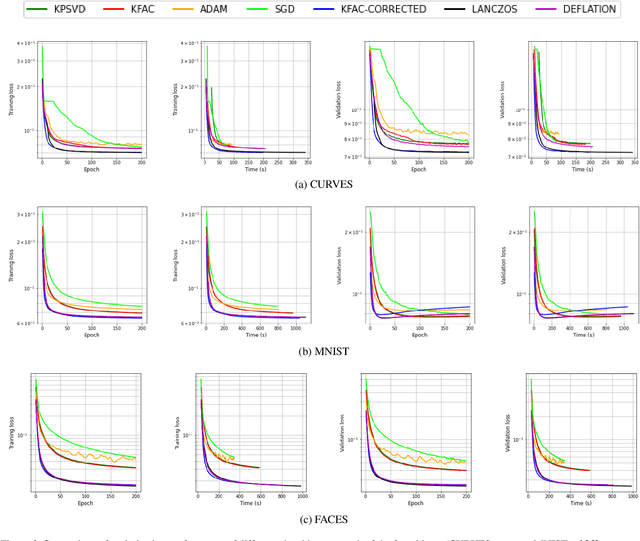
Several studies have shown the ability of natural gradient descent to minimize the objective function more efficiently than ordinary gradient descent based methods. However, the bottleneck of this approach for training deep neural networks lies in the prohibitive cost of solving a large dense linear system corresponding to the Fisher Information Matrix (FIM) at each iteration. This has motivated various approximations of either the exact FIM or the empirical one. The most sophisticated of these is KFAC, which involves a Kronecker-factored block diagonal approximation of the FIM. With only a slight additional cost, a few improvements of KFAC from the standpoint of accuracy are proposed. The common feature of the four novel methods is that they rely on a direct minimization problem, the solution of which can be computed via the Kronecker product singular value decomposition technique. Experimental results on the three standard deep auto-encoder benchmarks showed that they provide more accurate approximations to the FIM. Furthermore, they outperform KFAC and state-of-the-art first-order methods in terms of optimization speed.