Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEffects of Word Embeddings on Neural Network-based Pitch Accent Detection
Paper and Code
Jun 07, 2018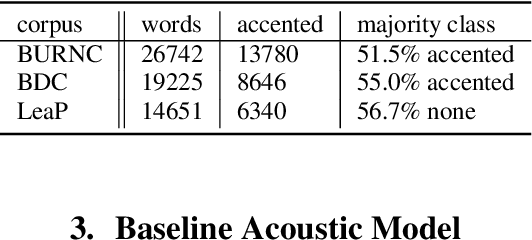
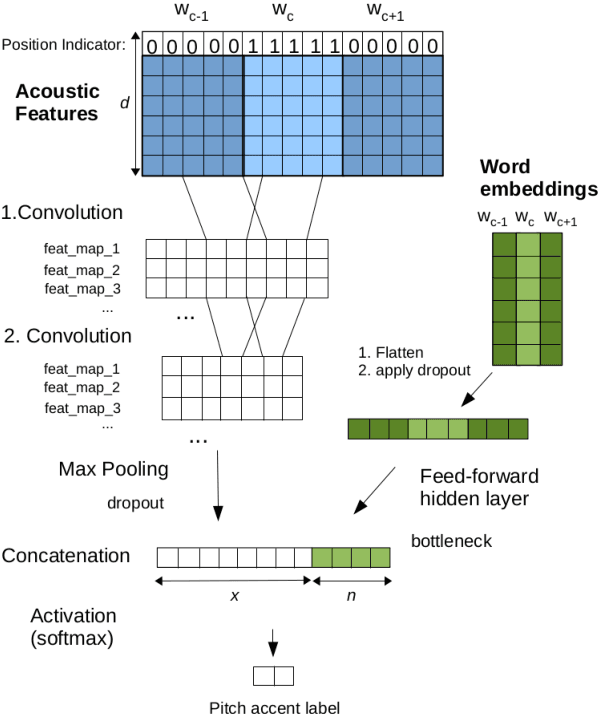
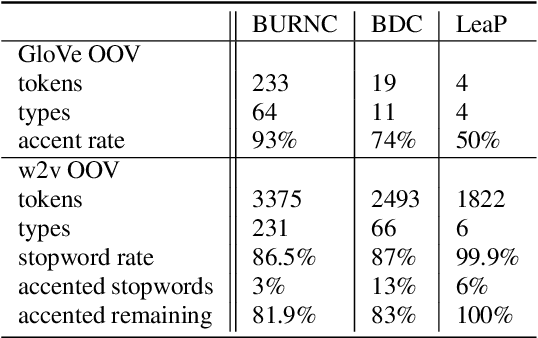
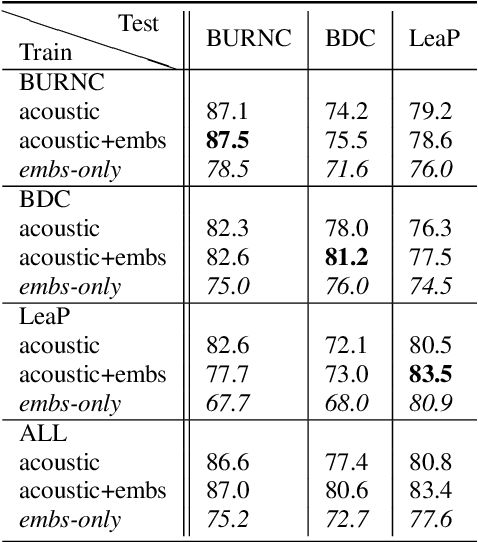
Pitch accent detection often makes use of both acoustic and lexical features based on the fact that pitch accents tend to correlate with certain words. In this paper, we extend a pitch accent detector that involves a convolutional neural network to include word embeddings, which are state-of-the-art vector representations of words. We examine the effect these features have on within-corpus and cross-corpus experiments on three English datasets. The results show that while word embeddings can improve the performance in corpus-dependent experiments, they also have the potential to make generalization to unseen data more challenging.
* This is an updated version of the paper that has been accepted at
Speech Prosody 2018 and published on the ISCA archive. The updates consist of
minor corrections that do not change the main conclusions in this work
View paper on