 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEffects of Using Synthetic Data on Deep Recommender Models' Performance
Paper and Code
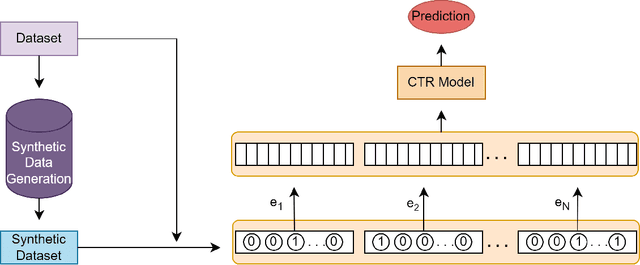
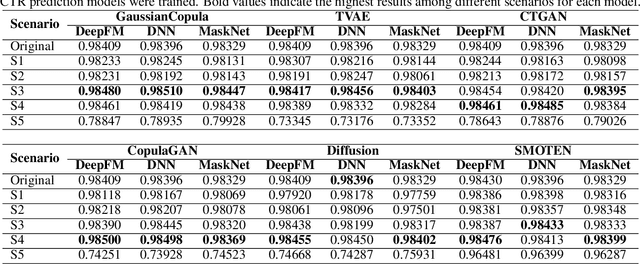
Recommender systems are essential for enhancing user experiences by suggesting items based on individual preferences. However, these systems frequently face the challenge of data imbalance, characterized by a predominance of negative interactions over positive ones. This imbalance can result in biased recommendations favoring popular items. This study investigates the effectiveness of synthetic data generation in addressing data imbalances within recommender systems. Six different methods were used to generate synthetic data. Our experimental approach involved generating synthetic data using these methods and integrating the generated samples into the original dataset. Our results show that the inclusion of generated negative samples consistently improves the Area Under the Curve (AUC) scores. The significant impact of synthetic negative samples highlights the potential of data augmentation strategies to address issues of data sparsity and imbalance, ultimately leading to improved performance of recommender systems.