 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEffects of Model Misspecification on Bayesian Bandits: Case Studies in UX Optimization
Paper and Code
Oct 07, 2020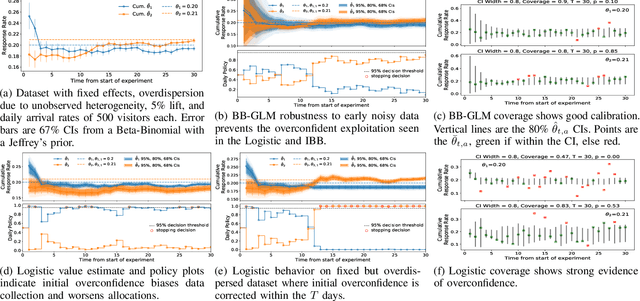
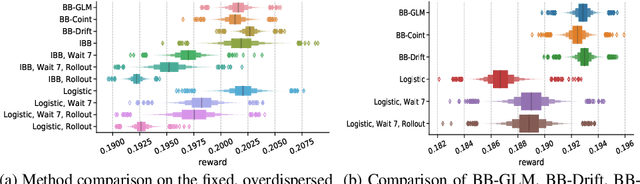


Bayesian bandits using Thompson Sampling have seen increasing success in recent years. Yet existing value models (of rewards) are misspecified on many real-world problem. We demonstrate this on the User Experience Optimization (UXO) problem, providing a novel formulation as a restless, sleeping bandit with unobserved confounders plus optional stopping. Our case studies show how common misspecifications can lead to sub-optimal rewards, and we provide model extensions to address these, along with a scientific model building process practitioners can adopt or adapt to solve their own unique problems. To our knowledge, this is the first study showing the effects of overdispersion on bandit explore/exploit efficacy, tying the common notions of under- and over-confidence to over- and under-exploration, respectively. We also present the first model to exploit cointegration in a restless bandit, demonstrating that finite regret and fast and consistent optional stopping are possible by moving beyond simpler windowing, discounting, and drift models.