Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEffective Subtree Encoding for Easy-First Dependency Parsing
Paper and Code


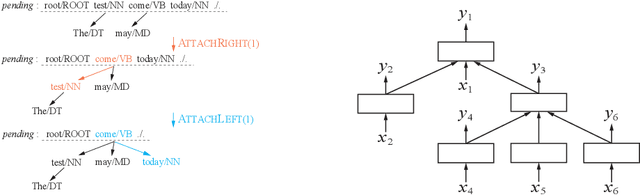

Easy-first parsing relies on subtree re-ranking to build the complete parse tree. Whereas the intermediate state of parsing processing are represented by various subtrees, whose internal structural information is the key lead for later parsing action decisions, we explore a better representation for such subtrees. In detail, this work introduces a bottom-up subtree encoder based on the child-sum tree-LSTM. Starting from an easy-first dependency parser without other handcraft features, we show that the effective subtree encoder does promote the parsing process, and is able to make a greedy search easy-first parser achieve promising results on benchmark treebanks compared to state-of-the-art baselines.
View paper on