 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEffective and Interpretable Information Aggregation with Capacity Networks
Paper and Code
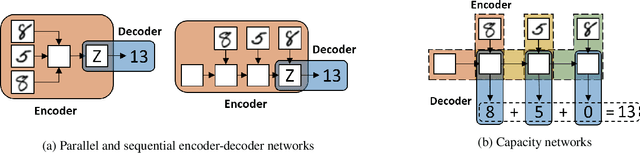
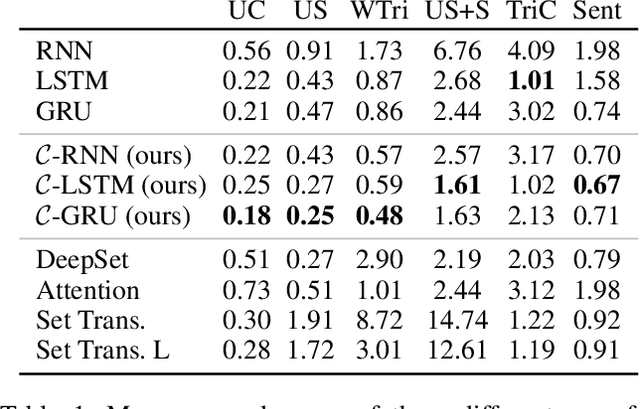
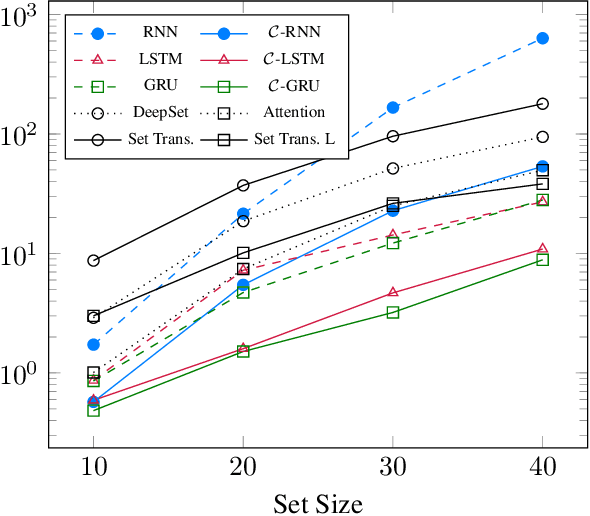
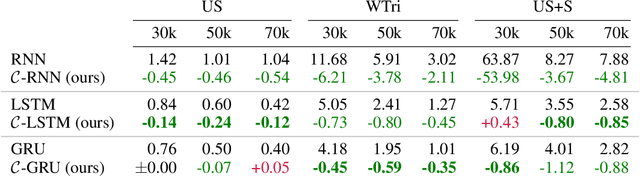
How to aggregate information from multiple instances is a key question multiple instance learning. Prior neural models implement different variants of the well-known encoder-decoder strategy according to which all input features are encoded a single, high-dimensional embedding which is then decoded to generate an output. In this work, inspired by Choquet capacities, we propose Capacity networks. Unlike encoder-decoders, Capacity networks generate multiple interpretable intermediate results which can be aggregated in a semantically meaningful space to obtain the final output. Our experiments show that implementing this simple inductive bias leads to improvements over different encoder-decoder architectures in a wide range of experiments. Moreover, the interpretable intermediate results make Capacity networks interpretable by design, which allows a semantically meaningful inspection, evaluation, and regularization of the network internals.