 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEDIT: Enhancing Vision Transformers by Mitigating Attention Sink through an Encoder-Decoder Architecture
Paper and Code
Apr 09, 2025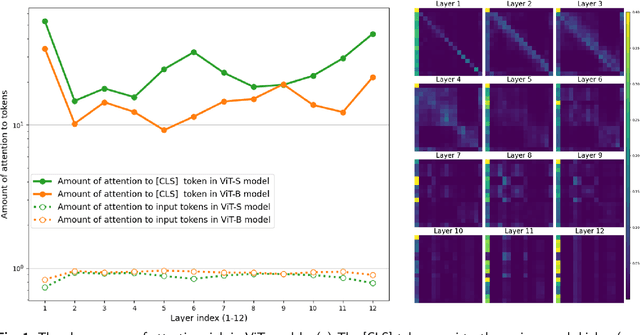
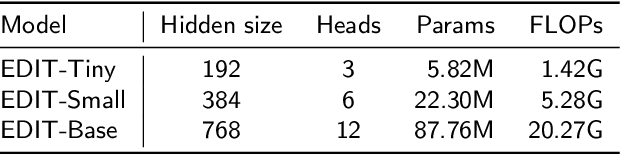
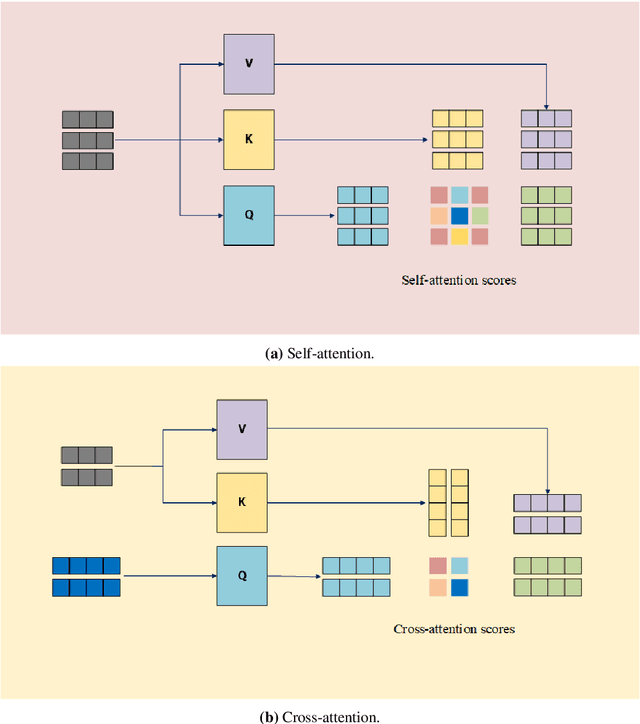
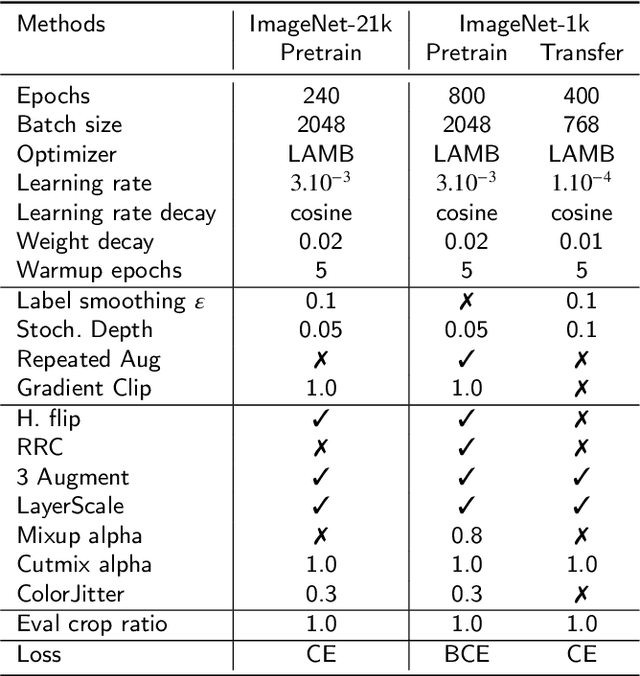
In this paper, we propose EDIT (Encoder-Decoder Image Transformer), a novel architecture designed to mitigate the attention sink phenomenon observed in Vision Transformer models. Attention sink occurs when an excessive amount of attention is allocated to the [CLS] token, distorting the model's ability to effectively process image patches. To address this, we introduce a layer-aligned encoder-decoder architecture, where the encoder utilizes self-attention to process image patches, while the decoder uses cross-attention to focus on the [CLS] token. Unlike traditional encoder-decoder framework, where the decoder depends solely on high-level encoder representations, EDIT allows the decoder to extract information starting from low-level features, progressively refining the representation layer by layer. EDIT is naturally interpretable demonstrated through sequential attention maps, illustrating the refined, layer-by-layer focus on key image features. Experiments on ImageNet-1k and ImageNet-21k, along with transfer learning tasks, show that EDIT achieves consistent performance improvements over DeiT3 models. These results highlight the effectiveness of EDIT's design in addressing attention sink and improving visual feature extraction.