 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEar2Face: Deep Biometric Modality Mapping
Paper and Code
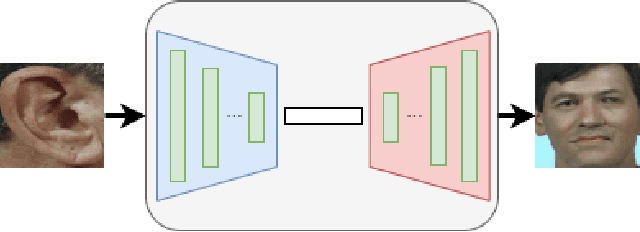
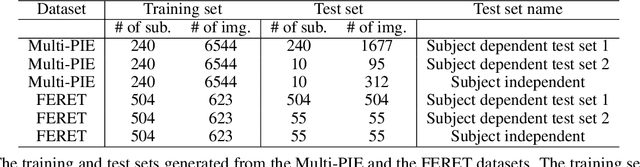
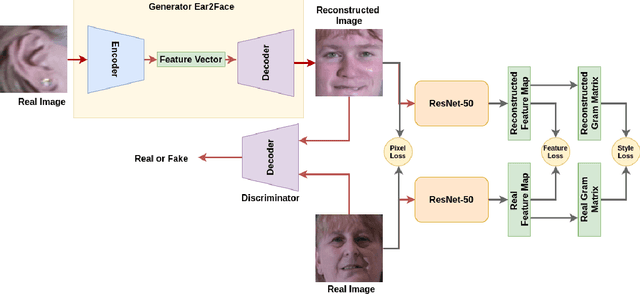

In this paper, we explore the correlation between different visual biometric modalities. For this purpose, we present an end-to-end deep neural network model that learns a mapping between the biometric modalities. Namely, our goal is to generate a frontal face image of a subject given his/her ear image as the input. We formulated the problem as a paired image-to-image translation task and collected datasets of ear and face image pairs from the Multi-PIE and FERET datasets to train our GAN-based models. We employed feature reconstruction and style reconstruction losses in addition to adversarial and pixel losses. We evaluated the proposed method both in terms of reconstruction quality and in terms of person identification accuracy. To assess the generalization capability of the learned mapping models, we also run cross-dataset experiments. That is, we trained the model on the FERET dataset and tested it on the Multi-PIE dataset and vice versa. We have achieved very promising results, especially on the FERET dataset, generating visually appealing face images from ear image inputs. Moreover, we attained a very high cross-modality person identification performance, for example, reaching 90.9% Rank-10 identification accuracy on the FERET dataset.