 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDynamical loss functions shape landscape topography and improve learning in artificial neural networks
Paper and Code
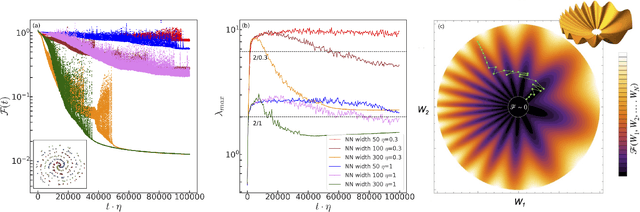
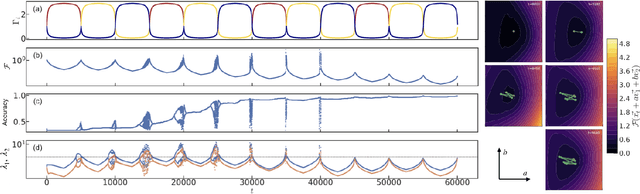
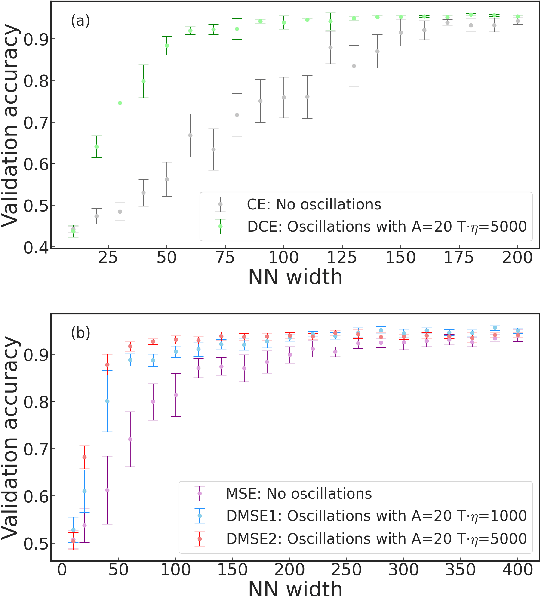
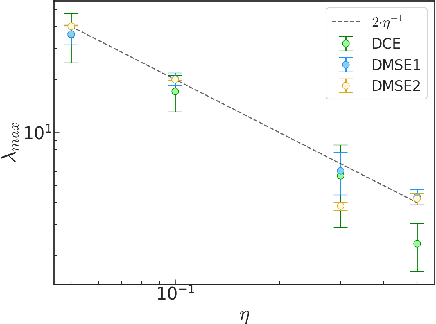
Dynamical loss functions are derived from standard loss functions used in supervised classification tasks, but they are modified such that the contribution from each class periodically increases and decreases. These oscillations globally alter the loss landscape without affecting the global minima. In this paper, we demonstrate how to transform cross-entropy and mean squared error into dynamical loss functions. We begin by discussing the impact of increasing the size of the neural network or the learning rate on the learning process. Building on this intuition, we propose several versions of dynamical loss functions and show how they significantly improve validation accuracy for networks of varying sizes. Finally, we explore how the landscape of these dynamical loss functions evolves during training, highlighting the emergence of instabilities that may be linked to edge-of-instability minimization.