 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDynamical Audio-Visual Navigation: Catching Unheard Moving Sound Sources in Unmapped 3D Environments
Paper and Code
Jan 12, 2022
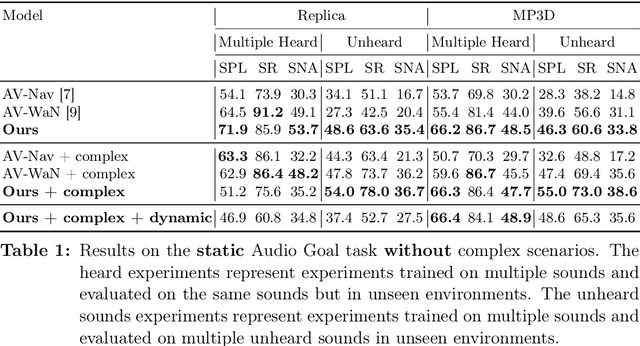
Recent work on audio-visual navigation targets a single static sound in noise-free audio environments and struggles to generalize to unheard sounds. We introduce the novel dynamic audio-visual navigation benchmark in which an embodied AI agent must catch a moving sound source in an unmapped environment in the presence of distractors and noisy sounds. We propose an end-to-end reinforcement learning approach that relies on a multi-modal architecture that fuses the spatial audio-visual information from a binaural audio signal and spatial occupancy maps to encode the features needed to learn a robust navigation policy for our new complex task settings. We demonstrate that our approach outperforms the current state-of-the-art with better generalization to unheard sounds and better robustness to noisy scenarios on the two challenging 3D scanned real-world datasets Replica and Matterport3D, for the static and dynamic audio-visual navigation benchmarks. Our novel benchmark will be made available at http://dav-nav.cs.uni-freiburg.de.