 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDynamic Regions Graph Neural Networks for Spatio-Temporal Reasoning
Paper and Code

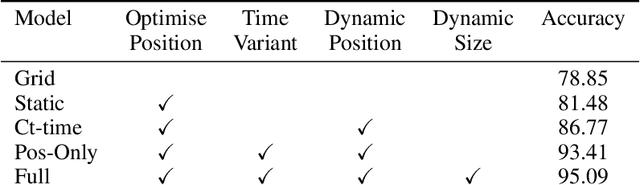
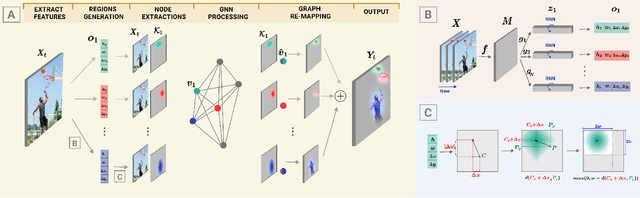
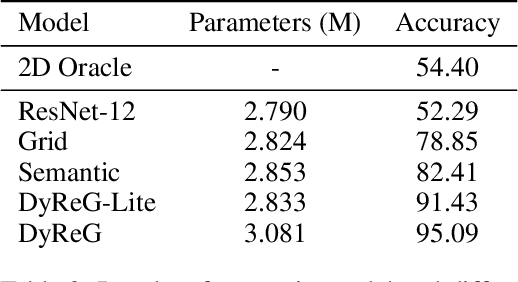
Graph Neural Networks are perfectly suited to capture latent interactions occurring in the spatio-temporal domain. But when an explicit structure is not available, as in the visual domain, it is not obvious what atomic elements should be represented as nodes. They should depend on the context and the kinds of relations that we are interested in. We are focusing on modeling relations between instances by proposing a method that takes advantage of the locality assumption to create nodes that are clearly localised in space. Current works are using external object detectors or fixed regions to extract features corresponding to graph nodes, while we propose a module for generating the regions associated with each node dynamically, without explicit object-level supervision. Conditioned on the input, for each node we predict the location and size of a region and use them to pool node features using a differentiable mechanism. Constructing these localised, adaptive nodes makes our model biased towards object-centric representations and we show that it improves the modeling of visual interactions. By relying on a few localized nodes, our method learns to focus on salient regions leading to a more explainable model. Our model achieves superior results on video classification tasks involving instance interactions.