 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDynamic Range Reduction via Branch-and-Bound
Paper and Code
Sep 17, 2024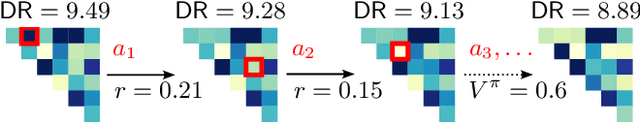

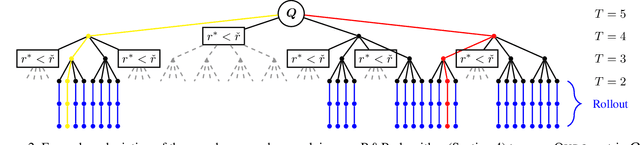

The demand for high-performance computing in machine learning and artificial intelligence has led to the development of specialized hardware accelerators like Tensor Processing Units (TPUs), Graphics Processing Units (GPUs), and Field-Programmable Gate Arrays (FPGAs). A key strategy to enhance these accelerators is the reduction of precision in arithmetic operations, which increases processing speed and lowers latency - crucial for real-time AI applications. Precision reduction minimizes memory bandwidth requirements and energy consumption, essential for large-scale and mobile deployments, and increases throughput by enabling more parallel operations per cycle, maximizing hardware resource utilization. This strategy is equally vital for solving NP-hard quadratic unconstrained binary optimization (QUBO) problems common in machine learning, which often require high precision for accurate representation. Special hardware solvers, such as quantum annealers, benefit significantly from precision reduction. This paper introduces a fully principled Branch-and-Bound algorithm for reducing precision needs in QUBO problems by utilizing dynamic range as a measure of complexity. Experiments validate our algorithm's effectiveness on an actual quantum annealer.