 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDynamic Pricing and Learning with Long-term Reference Effects
Paper and Code
Feb 19, 2024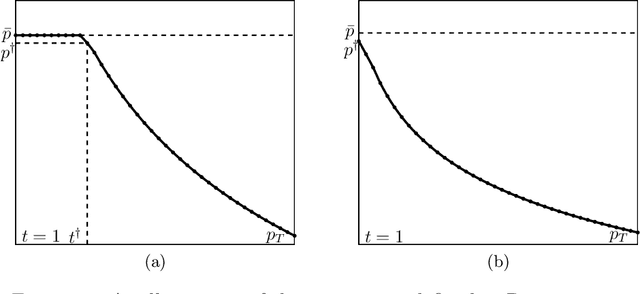
We consider a dynamic pricing problem where customer response to the current price is impacted by the customer price expectation, aka reference price. We study a simple and novel reference price mechanism where reference price is the average of the past prices offered by the seller. As opposed to the more commonly studied exponential smoothing mechanism, in our reference price mechanism the prices offered by seller have a longer term effect on the future customer expectations. We show that under this mechanism, a markdown policy is near-optimal irrespective of the parameters of the model. This matches the common intuition that a seller may be better off by starting with a higher price and then decreasing it, as the customers feel like they are getting bargains on items that are ordinarily more expensive. For linear demand models, we also provide a detailed characterization of the near-optimal markdown policy along with an efficient way of computing it. We then consider a more challenging dynamic pricing and learning problem, where the demand model parameters are apriori unknown, and the seller needs to learn them online from the customers' responses to the offered prices while simultaneously optimizing revenue. The objective is to minimize regret, i.e., the $T$-round revenue loss compared to a clairvoyant optimal policy. This task essentially amounts to learning a non-stationary optimal policy in a time-variant Markov Decision Process (MDP). For linear demand models, we provide an efficient learning algorithm with an optimal $\tilde{O}(\sqrt{T})$ regret upper bound.