 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDynamic Large Spatial Covariance Matrix Estimation in Application to Semiparametric Model Construction via Variable Clustering: the SCE approach
Paper and Code
Jun 23, 2011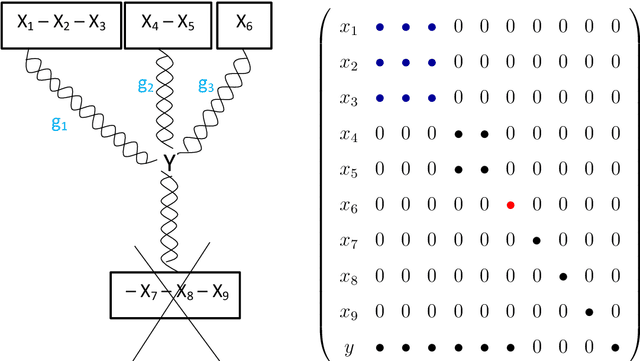
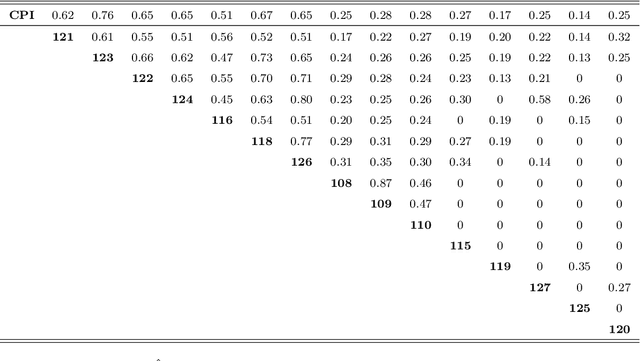
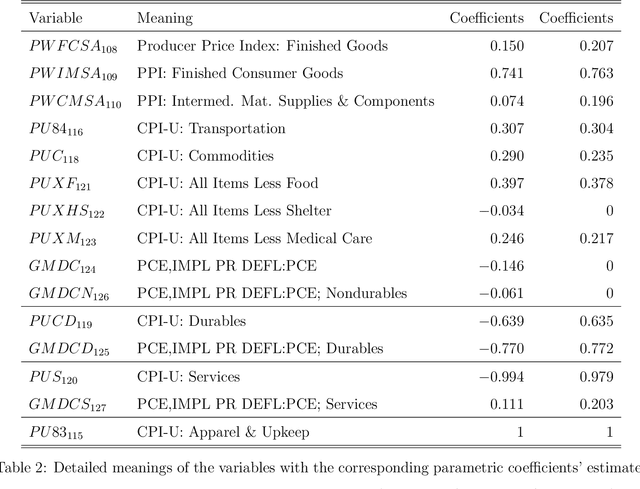
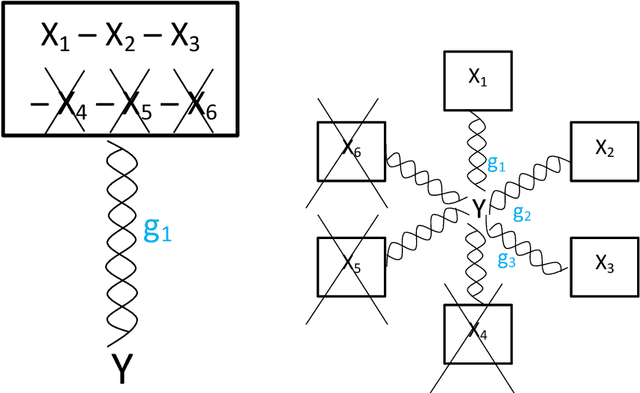
To better understand the spatial structure of large panels of economic and financial time series and provide a guideline for constructing semiparametric models, this paper first considers estimating a large spatial covariance matrix of the generalized $m$-dependent and $\beta$-mixing time series (with $J$ variables and $T$ observations) by hard thresholding regularization as long as ${{\log J \, \cx^*(\ct)}}/{T} = \Co(1)$ (the former scheme with some time dependence measure $\cx^*(\ct)$) or $\log J /{T} = \Co(1)$ (the latter scheme with some upper bounded mixing coefficient). We quantify the interplay between the estimators' consistency rate and the time dependence level, discuss an intuitive resampling scheme for threshold selection, and also prove a general cross-validation result justifying this. Given a consistently estimated covariance (correlation) matrix, by utilizing its natural links with graphical models and semiparametrics, after "screening" the (explanatory) variables, we implement a novel forward (and backward) label permutation procedure to cluster the "relevant" variables and construct the corresponding semiparametric model, which is further estimated by the groupwise dimension reduction method with sign constraints. We call this the SCE (screen - cluster - estimate) approach for modeling high dimensional data with complex spatial structure. Finally we apply this method to study the spatial structure of large panels of economic and financial time series and find the proper semiparametric structure for estimating the consumer price index (CPI) to illustrate its superiority over the linear models.