 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDual Instruction Tuning with Large Language Models for Mathematical Reasoning
Paper and Code
Mar 27, 2024
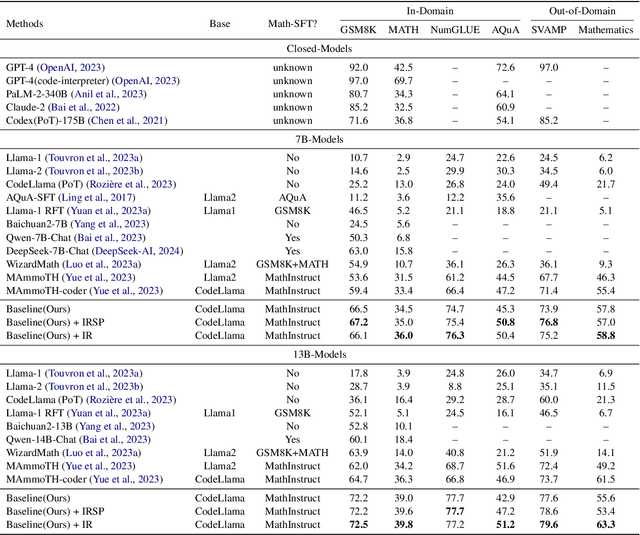


Recent advancements highlight the success of instruction tuning with large language models (LLMs) utilizing Chain-of-Thought (CoT) data for mathematical reasoning tasks. Despite the fine-tuned LLMs, challenges persist, such as incorrect, missing, and redundant steps in CoT generation leading to inaccuracies in answer predictions. To alleviate this problem, we propose a dual instruction tuning strategy to meticulously model mathematical reasoning from both forward and reverse directions. This involves introducing the Intermediate Reasoning State Prediction task (forward reasoning) and the Instruction Reconstruction task (reverse reasoning) to enhance the LLMs' understanding and execution of instructions. Training instances for these tasks are constructed based on existing mathematical instruction tuning datasets. Subsequently, LLMs undergo multi-task fine-tuning using both existing mathematical instructions and the newly created data. Comprehensive experiments validate the effectiveness and domain generalization of the dual instruction tuning strategy across various mathematical reasoning tasks.