 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDT-SV: A Transformer-based Time-domain Approach for Speaker Verification
Paper and Code
May 26, 2022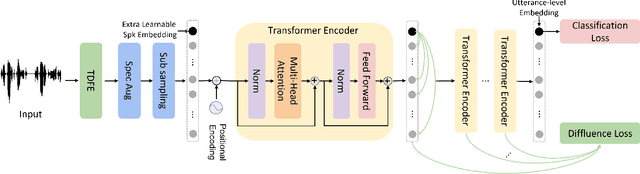
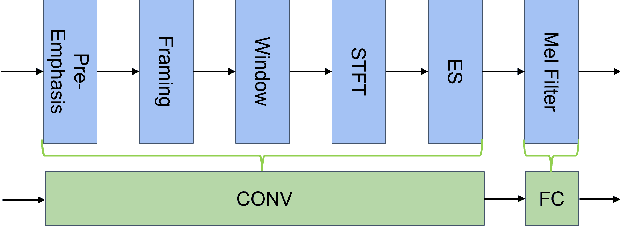
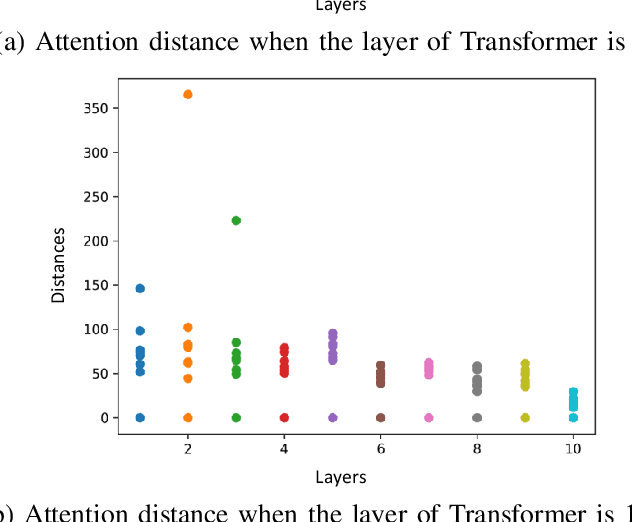
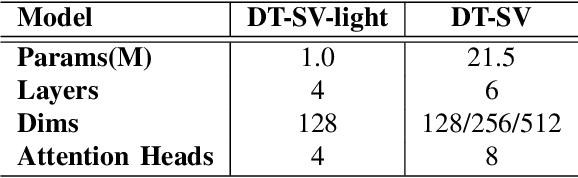
Speaker verification (SV) aims to determine whether the speaker's identity of a test utterance is the same as the reference speech. In the past few years, extracting speaker embeddings using deep neural networks for SV systems has gone mainstream. Recently, different attention mechanisms and Transformer networks have been explored widely in SV fields. However, utilizing the original Transformer in SV directly may have frame-level information waste on output features, which could lead to restrictions on capacity and discrimination of speaker embeddings. Therefore, we propose an approach to derive utterance-level speaker embeddings via a Transformer architecture that uses a novel loss function named diffluence loss to integrate the feature information of different Transformer layers. Therein, the diffluence loss aims to aggregate frame-level features into an utterance-level representation, and it could be integrated into the Transformer expediently. Besides, we also introduce a learnable mel-fbank energy feature extractor named time-domain feature extractor that computes the mel-fbank features more precisely and efficiently than the standard mel-fbank extractor. Combining Diffluence loss and Time-domain feature extractor, we propose a novel Transformer-based time-domain SV model (DT-SV) with faster training speed and higher accuracy. Experiments indicate that our proposed model can achieve better performance in comparison with other models.