 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDRT: A Lightweight Single Image Deraining Recursive Transformer
Paper and Code

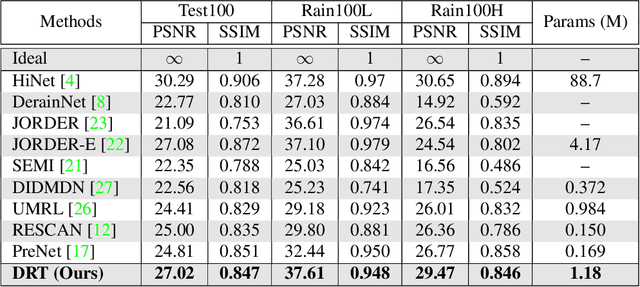
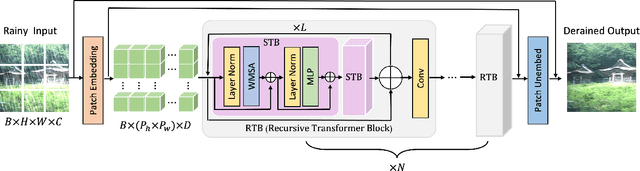
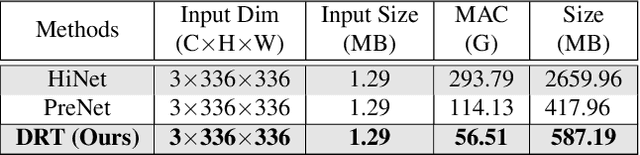
Over parameterization is a common technique in deep learning to help models learn and generalize sufficiently to the given task; nonetheless, this often leads to enormous network structures and consumes considerable computing resources during training. Recent powerful transformer-based deep learning models on vision tasks usually have heavy parameters and bear training difficulty. However, many dense-prediction low-level computer vision tasks, such as rain streak removing, often need to be executed on devices with limited computing power and memory in practice. Hence, we introduce a recursive local window-based self-attention structure with residual connections and propose deraining a recursive transformer (DRT), which enjoys the superiority of the transformer but requires a small amount of computing resources. In particular, through recursive architecture, our proposed model uses only 1.3% of the number of parameters of the current best performing model in deraining while exceeding the state-of-the-art methods on the Rain100L benchmark by at least 0.33 dB. Ablation studies also investigate the impact of recursions on derain outcomes. Moreover, since the model contains no deliberate design for deraining, it can also be applied to other image restoration tasks. Our experiment shows that it can achieve competitive results on desnowing. The source code and pretrained model can be found at https://github.com/YC-Liang/DRT.