 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDRIV100: In-The-Wild Multi-Domain Dataset and Evaluation for Real-World Domain Adaptation of Semantic Segmentation
Paper and Code



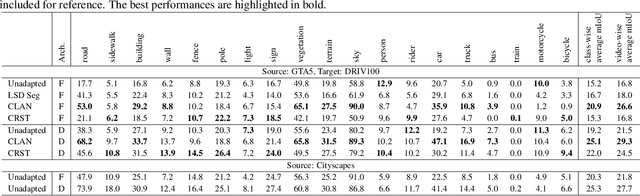
Together with the recent advances in semantic segmentation, many domain adaptation methods have been proposed to overcome the domain gap between training and deployment environments. However, most previous studies use limited combinations of source/target datasets, and domain adaptation techniques have never been thoroughly evaluated in a more challenging and diverse set of target domains. This work presents a new multi-domain dataset DRIV100 for benchmarking domain adaptation techniques on in-the-wild road-scene videos collected from the Internet. The dataset consists of pixel-level annotations for 100 videos selected to cover diverse scenes/domains based on two criteria; human subjective judgment and an anomaly score judged using an existing road-scene dataset. We provide multiple manually labeled ground-truth frames for each video, enabling a thorough evaluation of video-level domain adaptation where each video independently serves as the target domain. Using the dataset, we quantify domain adaptation performances of state-of-the-art methods and clarify the potential and novel challenges of domain adaptation techniques. The dataset is available at https://doi.org/10.5281/zenodo.4389243.