 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDREAM: Uncovering Mental Models behind Language Models
Paper and Code
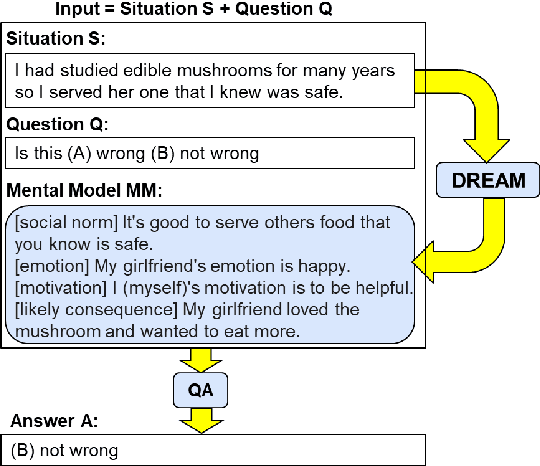

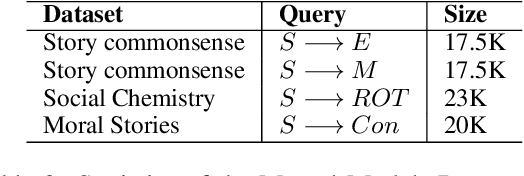
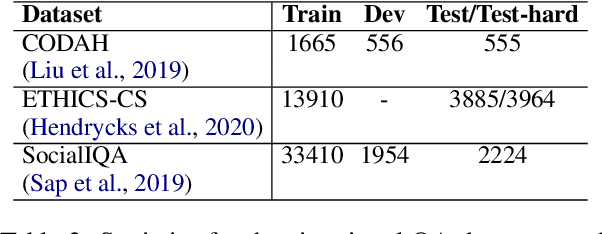
To what extent do language models (LMs) build "mental models" of a scene when answering situated questions (e.g., questions about a specific ethical dilemma)? While cognitive science has shown that mental models play a fundamental role in human problem-solving, it is unclear whether the high question-answering performance of existing LMs is backed by similar model building - and if not, whether that can explain their well-known catastrophic failures. We observed that Macaw, an existing T5-based LM, when probed provides somewhat useful but inadequate mental models for situational questions (estimated accuracy=43%, usefulness=21%, consistency=42%). We propose DREAM, a model that takes a situational question as input to produce a mental model elaborating the situation, without any additional task specific training data for mental models. It inherits its social commonsense through distant supervision from existing NLP resources. Our analysis shows that DREAM can produce significantly better mental models (estimated accuracy=67%, usefulness=37%, consistency=71%) compared to Macaw. Finally, mental models generated by DREAM can be used as additional context for situational QA tasks. This additional context improves the answer accuracy of a Macaw zero-shot model by between +1% and +4% (absolute) on three different datasets.