 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDRAFT: A Novel Framework to Reduce Domain Shifting in Self-supervised Learning and Its Application to Children's ASR
Paper and Code
Jun 16, 2022
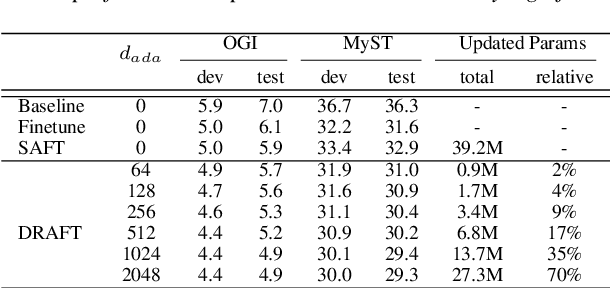

Self-supervised learning (SSL) in the pretraining stage using un-annotated speech data has been successful in low-resource automatic speech recognition (ASR) tasks. However, models trained through SSL are biased to the pretraining data which is usually different from the data used in finetuning tasks, causing a domain shifting problem, and thus resulting in limited knowledge transfer. We propose a novel framework, domain responsible adaptation and finetuning (DRAFT), to reduce domain shifting in pretrained speech models through an additional adaptation stage. In DRAFT, residual adapters (RAs) are inserted in the pretrained model to learn domain-related information with the same SSL loss as the pretraining stage. Only RA parameters are updated during the adaptation stage. DRAFT is agnostic to the type of SSL method used and is evaluated with three widely used approaches: APC, Wav2vec2.0, and HuBERT. On two child ASR tasks (OGI and MyST databases), using SSL models trained with un-annotated adult speech data (Librispeech), relative WER improvements of up to 19.7% are observed when compared to the pretrained models without adaptation. Additional experiments examined the potential of cross knowledge transfer between the two datasets and the results are promising, showing a broader usage of the proposed DRAFT framework.