 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDoing More by Doing Less: How Structured Partial Backpropagation Improves Deep Learning Clusters
Paper and Code
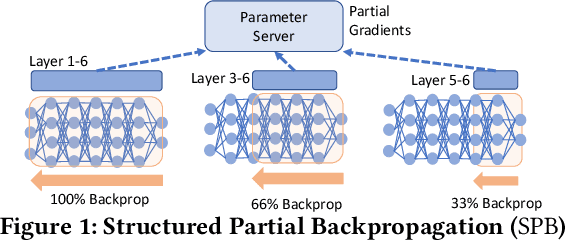



Many organizations employ compute clusters equipped with accelerators such as GPUs and TPUs for training deep learning models in a distributed fashion. Training is resource-intensive, consuming significant compute, memory, and network resources. Many prior works explore how to reduce training resource footprint without impacting quality, but their focus on a subset of the bottlenecks (typically only the network) limits their ability to improve overall cluster utilization. In this work, we exploit the unique characteristics of deep learning workloads to propose Structured Partial Backpropagation(SPB), a technique that systematically controls the amount of backpropagation at individual workers in distributed training. This simultaneously reduces network bandwidth, compute utilization, and memory footprint while preserving model quality. To efficiently leverage the benefits of SPB at cluster level, we introduce JigSaw, a SPB aware scheduler, which does scheduling at the iteration level for Deep Learning Training(DLT) jobs. We find that JigSaw can improve large scale cluster efficiency by as high as 28\%.