 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDoes human speech follow Benford's Law?
Paper and Code
Mar 24, 2022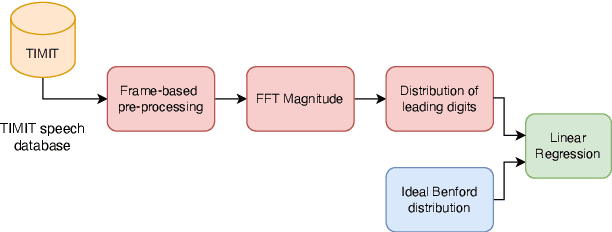
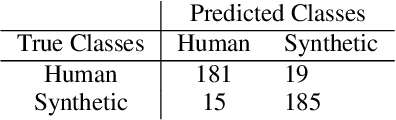
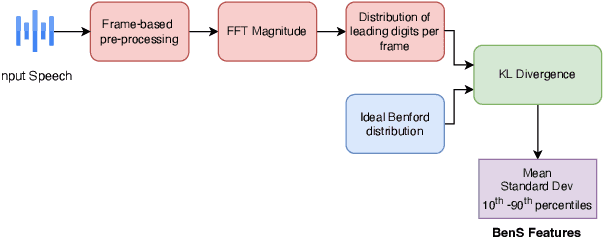
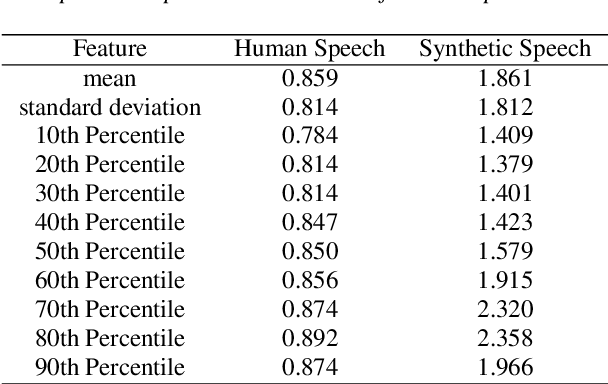
Researchers have observed that the frequencies of leading digits in many man-made and naturally occurring datasets follow a logarithmic curve, with digits that start with the number 1 accounting for $\sim 30\%$ of all numbers in the dataset and digits that start with the number 9 accounting for $\sim 5\%$ of all numbers in the dataset. This phenomenon, known as Benford's Law, is highly repeatable and appears in lists of numbers from electricity bills, stock prices, tax returns, house prices, death rates, lengths of rivers, and naturally occurring images. In this paper we demonstrate that human speech spectra also follow Benford's Law. We use this observation to motivate a new set of features that can be efficiently extracted from speech and demonstrate that these features can be used to classify between human speech and synthetic speech.