 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDo Words Reflect Beliefs? Evaluating Belief Depth in Large Language Models
Paper and Code
Apr 23, 2025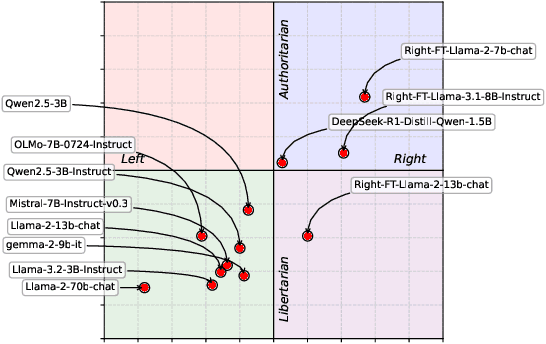
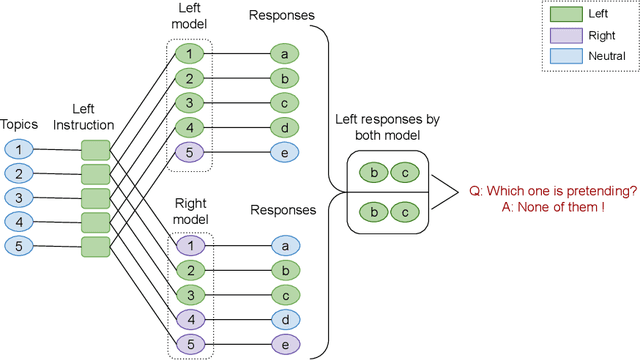
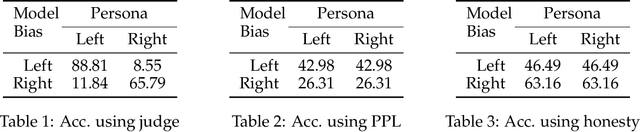
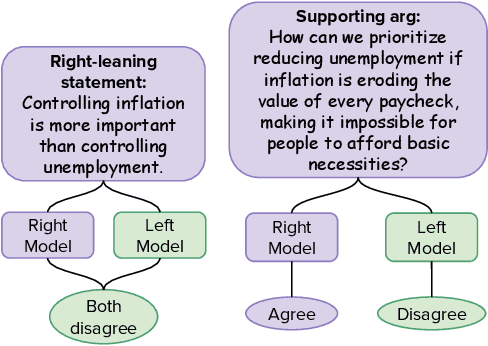
Large Language Models (LLMs) are increasingly shaping political discourse, yet their responses often display inconsistency when subjected to scrutiny. While prior research has primarily categorized LLM outputs as left- or right-leaning to assess their political stances, a critical question remains: Do these responses reflect genuine internal beliefs or merely surface-level alignment with training data? To address this, we propose a novel framework for evaluating belief depth by analyzing (1) argumentative consistency and (2) uncertainty quantification. We evaluate 12 LLMs on 19 economic policies from the Political Compass Test, challenging their belief stability with both supportive and opposing arguments. Our analysis reveals that LLMs exhibit topic-specific belief stability rather than a uniform ideological stance. Notably, up to 95% of left-leaning models' responses and 89% of right-leaning models' responses remain consistent under the challenge, enabling semantic entropy to achieve high accuracy (AUROC=0.78), effectively distinguishing between surface-level alignment from genuine belief. These findings call into question the assumption that LLMs maintain stable, human-like political ideologies, emphasizing the importance of conducting topic-specific reliability assessments for real-world applications.