 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDistributed Online Linear Quadratic Control for Linear Time-invariant Systems
Paper and Code
Sep 29, 2020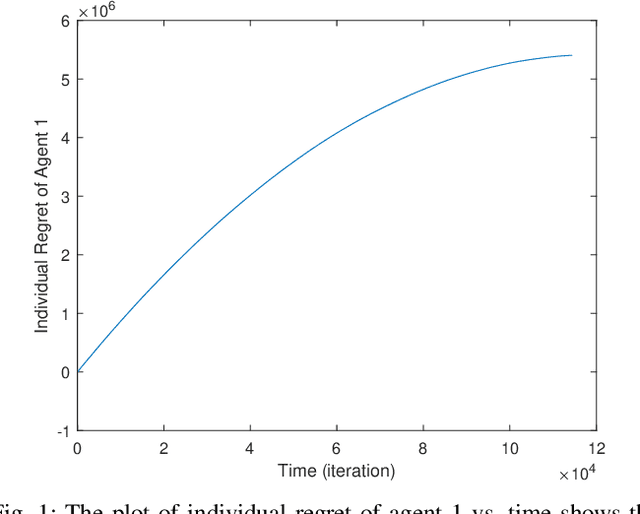
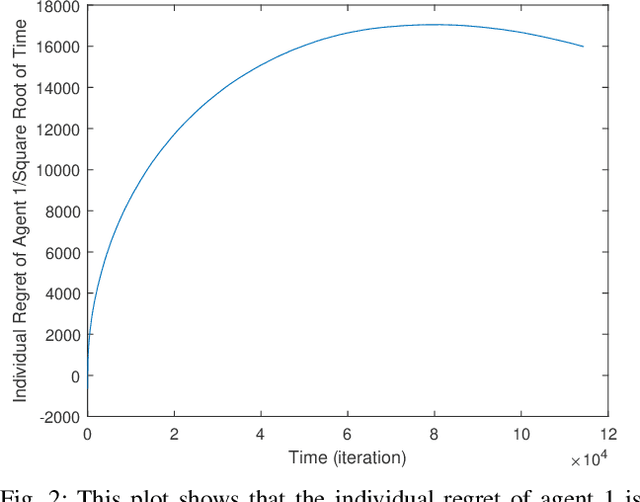
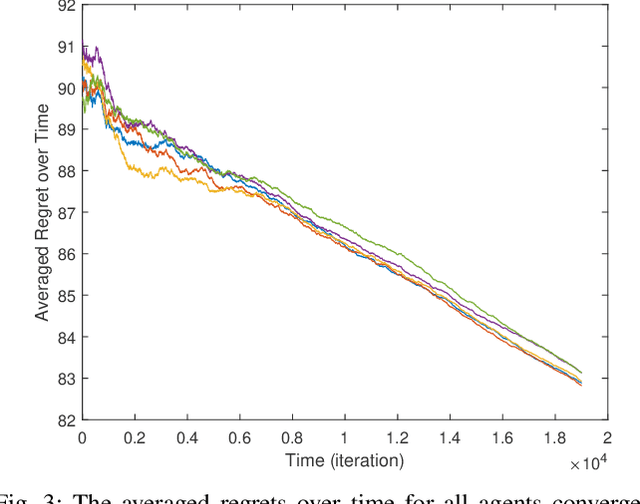
Classical linear quadratic (LQ) control centers around linear time-invariant (LTI) systems, where the control-state pairs introduce a quadratic cost with time-invariant parameters. Recent advancement in online optimization and control has provided novel tools to study LQ problems that are robust to time-varying cost parameters. Inspired by this line of research, we study the distributed online LQ problem for identical LTI systems. Consider a multi-agent network where each agent is modeled as an LTI system. The LTI systems are associated with decoupled, time-varying quadratic costs that are revealed sequentially. The goal of the network is to make the control sequence of all agents competitive to that of the best centralized policy in hindsight, captured by the notion of regret. We develop a distributed variant of the online LQ algorithm, which runs distributed online gradient descent with a projection to a semi-definite programming (SDP) to generate controllers. We establish a regret bound scaling as the square root of the finite time-horizon, implying that agents reach consensus as time grows. We further provide numerical experiments verifying our theoretical result.