 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDistributed Learning with Low Communication Cost via Gradient Boosting Untrained Neural Network
Paper and Code
Nov 10, 2020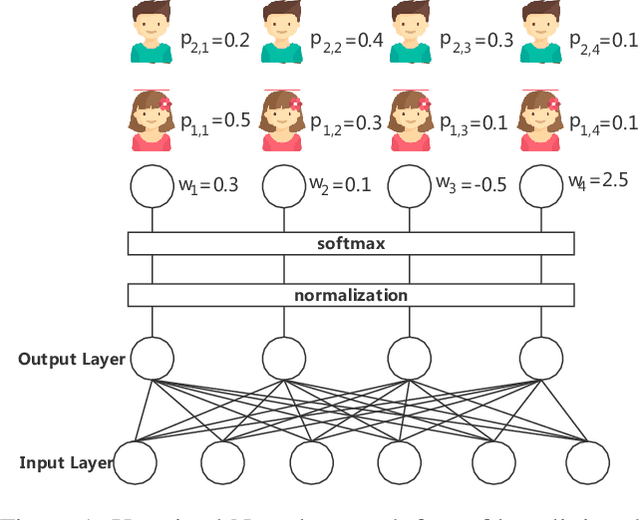
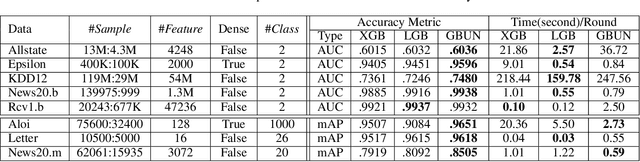
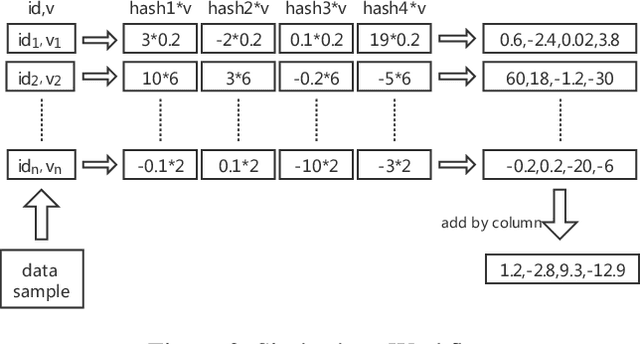
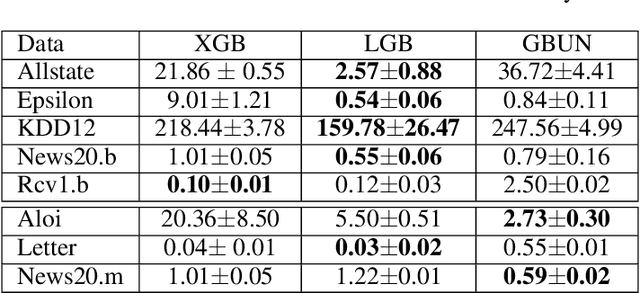
For high-dimensional data, there are huge communication costs for distributed GBDT because the communication volume of GBDT is related to the number of features. To overcome this problem, we propose a novel gradient boosting algorithm, the Gradient Boosting Untrained Neural Network(GBUN). GBUN ensembles the untrained randomly generated neural network that softly distributes data samples to multiple neuron outputs and dramatically reduces the communication costs for distributed learning. To avoid creating huge neural networks for high-dimensional data, we extend Simhash algorithm to mimic forward calculation of the neural network. Our experiments on multiple public datasets show that GBUN is as good as conventional GBDT in terms of prediction accuracy and much better than it in scaling property for distributed learning. Comparing to conventional GBDT varieties, GBUN speeds up the training process up to 13 times on the cluster with 64 machines, and up to 4614 times on the cluster with 100KB/s network bandwidth. Therefore, GBUN is not only an efficient distributed learning algorithm but also has great potentials for federated learning.