 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDistinctive 3D local deep descriptors
Paper and Code
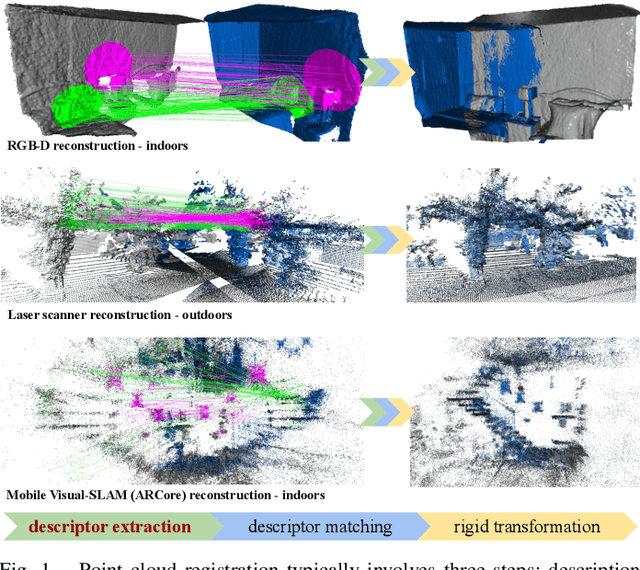
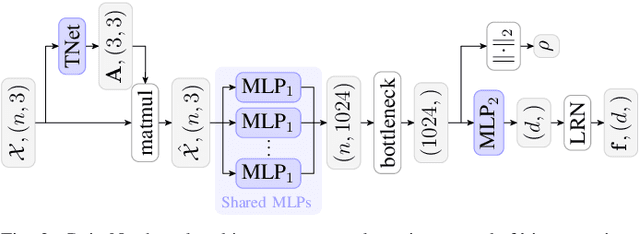

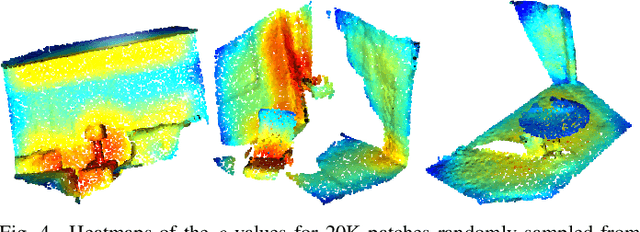
We present a simple but yet effective method for learning distinctive 3D local deep descriptors (DIPs) that can be used to register point clouds without requiring an initial alignment. Point cloud patches are extracted, canonicalised with respect to their estimated local reference frame and encoded into rotation-invariant compact descriptors by a PointNet-based deep neural network. DIPs can effectively generalise across different sensor modalities because they are learnt end-to-end from locally and randomly sampled points. Because DIPs encode only local geometric information, they are robust to clutter, occlusions and missing regions. We evaluate and compare DIPs against alternative hand-crafted and deep descriptors on several indoor and outdoor datasets consiting of point clouds reconstructed using different sensors. Results show that DIPs (i) achieve comparable results to the state-of-the-art on RGB-D indoor scenes (3DMatch dataset), (ii) outperform state-of-the-art by a large margin on laser-scanner outdoor scenes (ETH dataset), and (iii) generalise to indoor scenes reconstructed with the Visual-SLAM system of Android ARCore. Source code: https://github.com/fabiopoiesi/dip.