 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDistilling Wikipedia mathematical knowledge into neural network models
Paper and Code
Apr 13, 2021
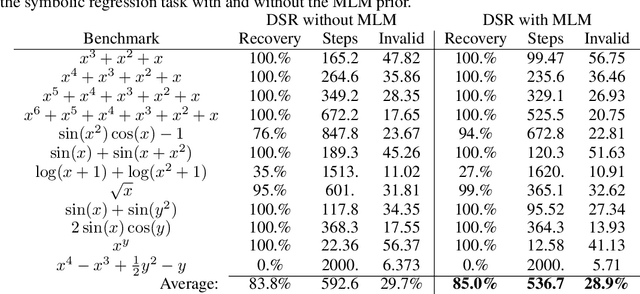
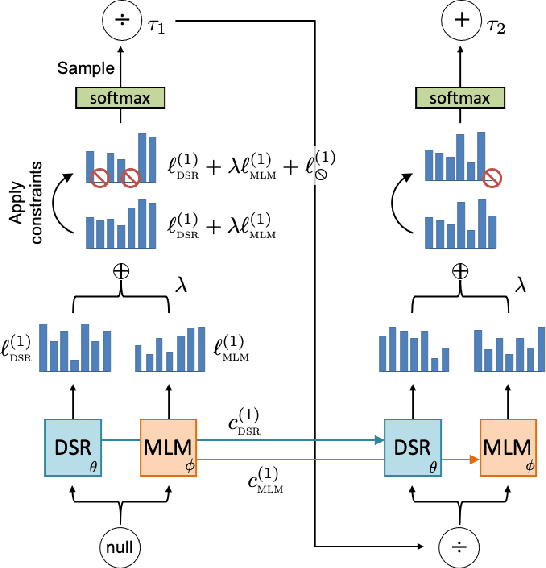
Machine learning applications to symbolic mathematics are becoming increasingly popular, yet there lacks a centralized source of real-world symbolic expressions to be used as training data. In contrast, the field of natural language processing leverages resources like Wikipedia that provide enormous amounts of real-world textual data. Adopting the philosophy of "mathematics as language," we bridge this gap by introducing a pipeline for distilling mathematical expressions embedded in Wikipedia into symbolic encodings to be used in downstream machine learning tasks. We demonstrate that a $\textit{mathematical}$ $\textit{language}$ $\textit{model}$ trained on this "corpus" of expressions can be used as a prior to improve the performance of neural-guided search for the task of symbolic regression.