 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDistill on the Go: Online knowledge distillation in self-supervised learning
Paper and Code
Apr 20, 2021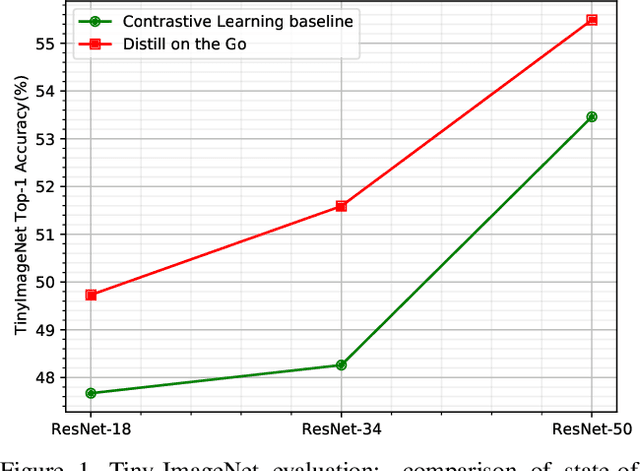
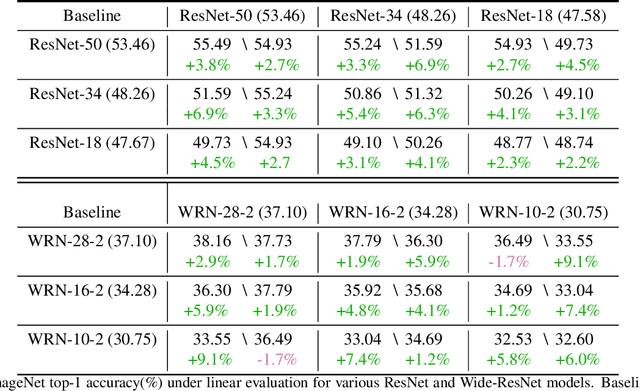
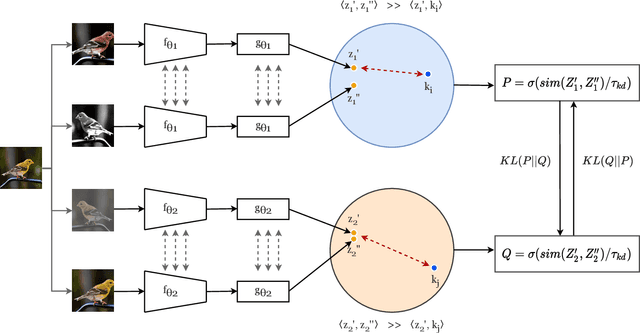
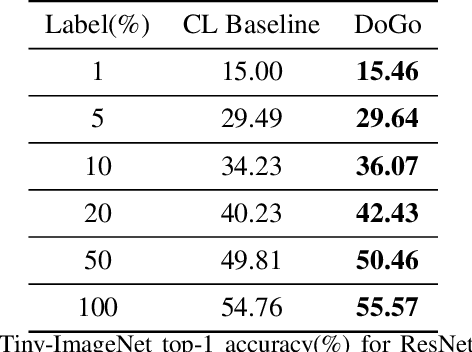
Self-supervised learning solves pretext prediction tasks that do not require annotations to learn feature representations. For vision tasks, pretext tasks such as predicting rotation, solving jigsaw are solely created from the input data. Yet, predicting this known information helps in learning representations useful for downstream tasks. However, recent works have shown that wider and deeper models benefit more from self-supervised learning than smaller models. To address the issue of self-supervised pre-training of smaller models, we propose Distill-on-the-Go (DoGo), a self-supervised learning paradigm using single-stage online knowledge distillation to improve the representation quality of the smaller models. We employ deep mutual learning strategy in which two models collaboratively learn from each other to improve one another. Specifically, each model is trained using self-supervised learning along with distillation that aligns each model's softmax probabilities of similarity scores with that of the peer model. We conduct extensive experiments on multiple benchmark datasets, learning objectives, and architectures to demonstrate the potential of our proposed method. Our results show significant performance gain in the presence of noisy and limited labels and generalization to out-of-distribution data.